容器
接下来,我们将深入探讨容器技术的发展历程,并揭示其成功的关键原因。
容器技术发展史
容器的发展不是一蹴而就的。作为一种“软件分发与运行标准”,容器在功能上像 Yum 和 Systemd 的结合,这就决定了容器技术只能缓慢地进入到 kernel 和 Linux 生态系统中,随着时间的流淌不断融入,等所有 Linux 发行版、应用软件和管理软件都成熟了以后,才能真正将这个新标准推广给所有 Linux 用户。
容器的发展按照时间顺序经历了文件系统隔离、进程访问隔离、系统资源限制、应用封装四步,下面我们一一展开。
文件系统隔离:Chroot
1979 年,美国计算机科学家 Bill Joy 提出并实现了 Chroot(Change Root)命令,内置到了第七版 Unix 系统中,它可以改变某个进程的文件系统根目录:限制这个进程以及所有子进程所能访问的文件系统,提升 Unix 系统安全性。后来人们发现这个工具可以很好地应用在软件的开发和测试过程中:它可以隔离多个软件之间的冲突和干扰,为它们提供相对独立的运行环境。
但是,作为一个安全工具,Chroot 还是不够安全,因为除了文件系统,软件还是可以通过大量的系统调用突破限制,这并不是一种完美的文件系统隔离方法。为了解决这个问题,2000 年 Linux Kernel 2.3.41 引入了 pivot_root 技术,它通过直接切换“根文件系统”的方式提高了安全性,今天常见的容器技术也都是优先使用 pivot_root 来做文件系统隔离的。当然,我们需要知道的是,即便到了 2023 年,文件系统的隔离依然不是完美的,如果你在 Docker 内运行了一个未知应用,你的系统还是有很大的被黑的风险。
进程访问隔离:Namespaces
命名空间,后端开发者肯定都不陌生,他就是 Java 和 Go 中的包名:给类安排一个前缀,避免同名的类搞混。但是 Linux 的 Namespaces 却不仅仅是为了防止同名混淆。自 2002 的 Kernel 2.4.19 开始,Namespaces 就被引入了 Linux 内核,而且它在刚刚发布的时候和 Chroot 干的事情是一样的:隔离文件系统。由于 Unix 一切皆文件的思想,可以把初代 Namespaces 看做一种更高级更完善的 Chroot。
后来,随着用户量的增加,大家迫切需要 Namespaces 把其它资源也隔离一下,到了 Kernel 5.6 时代,Namespaces 已经具备了文件系统、主机名、NIS 域名(一种 Unix/Linux 的域控制系统)、进程间通信管道(IPC)、进程编号(PID)、网络、用户和用户组、Cgroup、系统时间一共八种隔离能力。
Namespaces 是容器技术的坚实基础:它不是虚拟机,它没有搞一套虚拟的操作系统接口,而是忠实地把宿主机的信息暴露给了某个 namespace 内的进程,但是不同的 namespace 内的进程之间是相互看不见的。它们都以为是自己在独占操作系统的全部资源。
下面问题来了,软件不都是“有多少资源就占用多少资源”的吗?如果某个进程把系统资源吃完了该怎么办呢?轮到系统资源限制功能登场了。
系统资源限制:Cgroups
如果我们想抛弃虚拟机技术,用软件的方式直接限制某个进程所能消耗的资源上限,那么就需要内核、基础库、系统调用以及应用软件紧密协同配合。
2008 年,谷歌贡献的 Cgroups 第一次被合并进了 Kernel 2.6.24 中,自此,内核第一次拥有了完善的“进程资源控制”功能,这可以视为容器技术的第一声啼哭。发展到今天,Cgroups 的控制能力已经非常完善了,它可以限制、记录、隔离一个进程组所使用的全部物理资源,功能非常丰富:
- Block I/O(blkio):限制块设备(磁盘、SSD、USB 等)的 I/O 速率上限
- CPU Set(cpuset):限制任务能运行在哪些 CPU 核心上
- CPU Accounting(cpuacct):生成 Cgroup 中任务使用 CPU 的报告
- CPU (CPU):限制调度器分配的 CPU 时间
- Devices (devices):允许或者拒绝 Cgroup 中任务对设备的访问
- Freezer (freezer):挂起或者重启 Cgroup 中的任务
- Memory (memory):限制 Cgroup 中任务使用内存的量,并生成任务当前内存的使用情况报告
- Network Classifier(net_cls):为 Cgroup 中的报文设置上特定的 classid 标志,这样 tc 等工具就能根据标记对网络进行配置
- Network Priority (net_prio):对每个网络接口设置报文的优先级
- perf_event:识别任务的 Cgroup 成员,可以用来做性能分析
登录一台 Linux 系统,执行mount -t Cgroup就可以看到本机挂载了哪些 Cgroups 资源,如代码清单 2-1 所示。
root@PPHC ~ # mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)有了 Cgroups,我们就可以记录并限制一个或者几个进程所能使用的计算资源的上限了,万事俱备,只欠封装成应用了。
应用封装
昙花一现的 LXC
LXC 是第一代容器封装技术,也是 Docker 最早期采用的技术方案,但它虽然也把应用封装成了容器,但却是直接封装成的 pod,一个 pod 中包含多个软件,无法自定义。LXC 就像是新时代的 yum groupinstall 命令,虽然它确实属于容器技术,但是他的管理思维依然停留在“一次性安装多个软件”的阶段,价值有限,在 Docker 抛弃它以后,逐渐没落。
Docker:一夜爆红只需要一个好点子
2010 年,几个大胡子年轻人创立了一家名为 dotCloud 的 PaaS(平台即服务)公司,随后便获得了 YC(Y Combinator 风险投资公司)的投资,但是三年过去,随着谷歌、亚马逊、微软等巨头的入场,dotCloud 的业务每况愈下。终于,在 2013 年 3 月,他们决定将核心技术 Docker 开源,随后的一年,Docker 火爆全球。
Docker 的爆火在于它提出了一套恰逢其时的容器概念:① 以应用为中心 ② 可以派生版本 ③镜像可以上传并共享。
Docker 的技术优势
Docker 技术相比于 LXC,有了非常大的进步,它们架构上的巨大区别如图 2-6 所示。
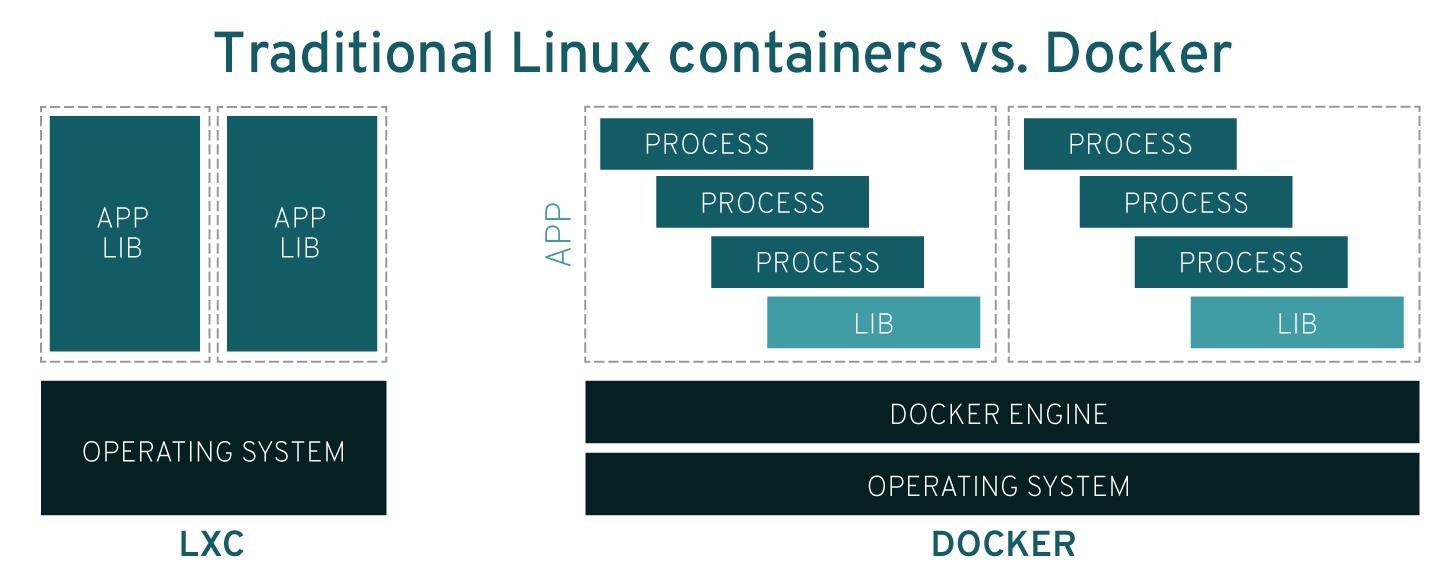
镜像技术开天辟地
如果必须找出 Docker 最有价值的创造,那一定是镜像。Docker 通过把整个操作系统的文件系统打包进镜像,真正实现了一次构建、处处运行。而在这之前,只有基于硬件虚拟化技术的虚拟机才能做到这一点,运行库虚拟化、虚拟机编程语言、解释型编程语言都做不到。
除了可以在任意支持 Docker 的 Linux 系统之间完美迁移之外,Docker 镜像还有一个巨大的创新:层。
“以应用为中心”的思想
Docker 第一次把部署一个软件所需要的环境和依赖放在一起看做了一整个单独的“应用”。而 LXC 容器依然是一种“对系统的封装”,可以视作标准化、轻量化的新时代虚拟机。
- 应用是独立的,可以随意部署的个体,像经典力学的规律,不随时间和空间的变化而变化。
- 对系统的封装依然是在某一个时刻在某个操作系统上用标准容器的方式安装了软件,随着时间的流逝,操作系统拥有不同的版本和不同的软件补丁,在不同的时间得到的最终产物并不一致。
镜像技术的核心——层
Docker 层是 Docker 镜像的构建块,它们共享相同的文件系统和元数据。每个层都包含对上一层的增量更改,这使得 Docker 镜像更加轻量级和可重用。Docker 使用 UnionFS(联合文件系统)技术将多个层组合在一起,形成一个统一的文件系统。
Docker 层的概念有以下几个特点:
- 共享:Docker 层可以在多个镜像和容器之间共享,这有助于减少存储空间的浪费。
- 增量:每一层都是对上一层的增量更改,这意味着你只需要复制发生变化的部分,而不是整个文件系统。
- 可读性:Docker 层的文件系统是只读的,这意味着你不能直接修改它。但是,你可以在运行时创建新的层来保存更改。
- 可缓存:Docker 使用缓存机制来提高构建速度。当构建一个新的镜像时,Docker 会检查本地是否存在与新层相同的层,如果存在,则可以直接使用缓存的层,而不需要重新构建。
基于层的概念,每一个镜像拥有最多 127 个版本,你不仅可以随时修改、提交、回退版本,还可以直接基于基础镜像打造自己的软件,以我们的静山平台为例,我们可以用一个简单的描述在一个 pod 内搭建好所需要的所有软件:
- 基于 CentOS 8 基础系统镜像构建新镜像
- 执行命令:yum 安装 Nginx
- 执行命令:yum 安装 php-fpm 8
- 执行命令:yum 安装 MySQL 8
- 执行命令:复制 Nginx 和 php-fpm 的配置文件进入镜像
- 设置启动命令:启动 php-fpm、Nginx 和 MySQL
我们将上述过程转化为一个名为 Dockerfile 的文本文件,该文件充当了我们想要构建的新镜像的配置文件。在本例中,我们基于基础的 CentOS 8 镜像创建了一个新的层,这一层进行了哪些修改,后续读者只需阅读 Dockerfile 即可全面了解。这在以前的传统运维过程中几乎是不可能的。这个由 Dockerfile 文本描述的基础运行环境成为了一套“不可变基础设施”。
当然,我们也可以将这个镜像上传到 DockerHub,向全球开放,其他人如果有类似的 LNMP 需求都可以使用我们的镜像。
本章后面的 2.8 节提供了可运行的 Dockerfile,具备动手能力的读者可以尝试自行编写 Dockerfile,并与代码清单 2-2 进行对照。
DockerHub 彻底改变了运维的工作性质
以前的运维,是做在小黑屋里,守着自己的几台机器,去网上扒各种资料,试图解决某一台机器遇到的某一个奇葩的问题。可能某一个不小心的yum update就导致某个系统组件无法启动,需要折腾好长时间,服务才能恢复服务。
有了 DockerHub 之后,运维也成了为开源软件做贡献一样令人激动的事情:人们可以在镜像社区中相互协作,逐层搭建出适合自己需求的镜像。你和你的代码将立即参与到了全球运维代码的分发流程中。
除了相互协作,在面对复杂的运维需求时,解决问题的过程也是被明文记录的,一旦你解决了这个问题,那你的配置文件便可以随意更换机器部署:一个正常运行的镜像,可以跨越十年光阴,从 E5-V4 上运行的 CentOS 7.0(Kernel 3.10.0)非常方便地迁移到 AMD EPYC™ 9654 上运行的 Centos Stream 9(Kernel 6.4.2)上,不用担心出现兼容问题。