OceanBase 设计思路
我们以最新的 OceanBase 4.0 版本的架构为目标进行讨论。
TiDB 底层数据叫分片,那 OceanBase 为什么叫分区呢?因为分片的意思只是数据被分开了(KV 数据库不同的 Key 之间本来也没有关系),但分区表示的是分区内部的数据之间是有联系的:OceanBase 的每个节点本身,依然是一个关系型数据库,拥有自己的 SQL 引擎、存储引擎和事务引擎。
简单的分区
OceanBase 在建表时就需要设定数据分区规则,之后每一行数据都属于且仅属于某个分区。在数据插入和查询的时候,需要找到这一行数据所在的区,进行针对性地路由。这和第一代分布式——中间件的思想一致。这么做相当于简单地并行执行多条 SQL,以数据切分和数据聚合为代价,让数据库并行起来。而这个数据切分和数据聚合的代价,可以很小,也可以很大,需要 OceanBase 进行精细的性能优化,我们下面还会说到。
分区之间,通过 Multi-Paxos 协议来同步数据:每一个逻辑分区都会有多个副本分布在多台机器上,只有其中一个副本会成为 leader,并接受写请求。这里的架构和 PolarDB 一样了,此时,客户端的一致性读需要网关(OBProxy)来判断,主从之间的同步是有可感知的延迟的。
节点存储架构
如图所示是 OceanBase 的官方存储架构图。
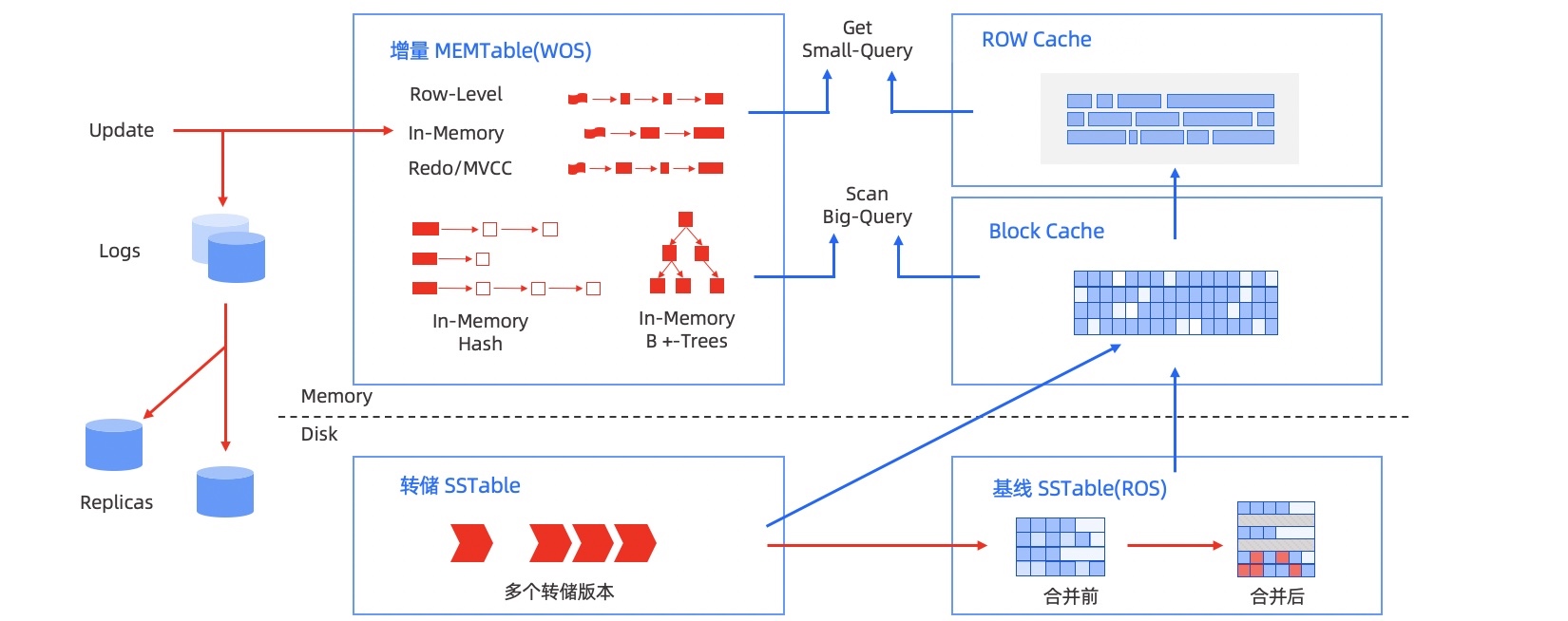
OceanBase 数据库的存储引擎基于 LSM Tree 架构,将数据分为静态基线数据(放在 SSTable 中)和动态增量数据(放在 MemTable 中)两部分,其中 SSTable 是只读的,一旦生成就不再被修改,存储于磁盘;MemTable 支持读写,存储于内存。数据库 DML 操作插入、更新、删除等首先写入 MemTable,等到 MemTable 达到一定大小时转储到磁盘成为 SSTable。在进行查询时,需要分别对 SSTable 和 MemTable 进行查询,并将查询结果进行归并,返回给 SQL 层归并后的查询结果。同时在内存实现了 Block Cache 和 Row cache,来避免对基线数据的随机读。
当内存的增量数据达到一定规模的时候,会触发增量数据和基线数据的合并,把增量数据落盘。同时每天晚上的空闲时刻,系统也会自动每日合并。
OceanBase 数据库本质上是一个基线加增量的存储引擎,在保持 LSM-Tree 架构优点的同时也借鉴了部分传统关系数据库存储引擎的优点。
以上是官方描述,笔者本来想简化一下,读了一遍觉得还是直接放上原文吧,原文描述的就非常得清晰精炼了:OceanBase 用内存 B+ 树和磁盘 LSM-Tree 共同构成了数据读写体系,和上一章中的 InnoDB 是多么像啊!只是 OceanBase 做的更细:跟 TiDB 相比,就像是在 TiKV 上面加了一层 Buffer Pool 一样。
还有一个细节:OceanBase 除了记录日志(Redo Log)并修改内存缓存(MemTable)之外,只要内存充足,白天 OceanBase 不会主动将内存缓存中的数据刷洗到 SSTable 里的,官方更推荐每天凌晨定时刷洗。这是什么思想?可以说是空间(内存)换时间,也可以说是拿未来的时间换现在的时间。
充分利用内存缓存
从基础电气属性上讲,磁盘一定是慢的,内存一定是快的,所以在数据量大于机器的内存容量时,各种数据库的性能差别可以聚焦到一个点上:内存利用效率,即热数据命中内存缓存的概率。
为了提升缓存命中率,OceanBase 设计了很多层内存缓存,尽全力避免了对磁盘的随机读取,只让 LSM-Tree 的磁盘承担它擅长的连续读任务,包子有肉不在褶上,商用环境中捶打过的软件就是不一样,如图 10-6 所示,功夫都在细节里:

- BloomFilter Cache:布隆过滤器缓存
- MemTable:同时使用 B+ 树和 HashTable 作为内存引擎,分别处理不同的场景
- Row Cache:存储 Get/MultiGet 查询的结果
- Block Index Cache:当需要访问某个宏块的微块时,提前装载这个宏块的微块索引
- Block Cache:像 Buffer Pool 一样缓存数据块(InnoDB 页)
- Fuse Row Cache:在 LSM-Tree 架构中, 同一行的修改可能存在于不同的 SSTable 中,在查询时需要对各个 SSTable 查询的结果进行熔合,对于熔合结果缓存可以更大幅度地支持热点行查询
- Partition Location Cache:用于缓存 Partition 的位置信息,帮助对一个查询进行路由
- Schema Cache:缓存数据表的元信息,用于执行计划的生成以及后续的查询
- Clog Cache:缓存 clog 数据,用于加速某些情况下 Paxos 日志的拉取
直接变身内存数据库
为了极致的性能,OceanBase 直接取消了 MySQL 中“后台进程每秒将 redo log 刷写到 ibd 文件”这一步,等于放大了集群宕机重启后恢复数据的时间(重启后需要大量的时间和磁盘 I/O 将 redo log 刷写入磁盘),然后把这件事放到半夜去做:
当内存的增量数据达到一定规模的时候,会触发增量数据和基线数据的合并,把增量数据落盘。同时每天晚上的空闲时刻,系统也会自动每日合并。
把一整天的新增和修改的数据全部放到内存里,相当于直接变身成了内存数据库(还会用 B 树和 Hashtable 存两份),确实是一种终极的性能优化手段,OceanBase 真有你的。
提升并行查询和数据聚合性能
传统的中间件 Sharding 技术中,也会做一些并行查询,但是它们做的都是纯客户端的查询:proxy 作为标准客户端,分别从多台机器拿到数据之后,用自己的内存进行数据处理,这个逻辑非常清晰,但有两个问题:1. 只能做简单的并行和聚合,复杂的做不了 2. 后端数据库相互之间无通信,没有很好地利用资源,总响应时间很长。
OceanBase 让一切尽可能地并行起来了:在某台机器上的 proxy(OBServer) 接到请求以后,它会担任协调者的角色,将任务并行地分发到多个其他的 OBServer 上执行;同时,将多个子计划划分到各个节点上以后,会在各节点之间建立 M*N 个网络通信 channel,并行地传输信息;此外,OceanBase 还对传统数据库的执行计划优化做了详细的拆分,对特定的关键词一个一个地做分布式优化,才最终达成了地表最强的成就。
由于本身就是为了兼容 MySQL 而设计的一种新技术实现,所以它拥有非常优秀的兼容性,和 MySQL 不兼容的情况很少,具体如图 10-7 所示。

OceanBase 对 CAP 和不可能三角的抉择
由于数据是分区的,所以当脑裂时,两个大脑的数据肯定已经不完整了,相当于两万行的表只剩一万行数据可以进行查询和更新,此时,如果 OceanBase 梗着脖子非要追求数据强一致,也是可以让所有的 OBProxy 拒绝服务的,但是 OceanBase 选择了继续苟着:互联网公司嘛,能实现最终一致性就行了,要啥自行车。
OceanBase 放弃了 CAP 和新不可能三角中的一致性,只能做到最终一致性:为了事务隔离和性能,哥忍了。
其实,不追求强一致和下一章中的终极高并发架构在思想上是一致的,这可能就是经历过大规模生产应用的数据库,被现实世界毒打过后的痕迹吧。
一句话概括 OceanBase:①世界第一性能的,②高度兼容 MySQL 的,③经历过生产系统考验的高性能分布式关系型数据库。