CTRL + K
TiDB 的设计思路
笔者抽象出的 TiDB 架构图如图 10-1 所示。

上图中的“SQL 层”就是解析 SQL 语句并将其转化为 KV 命令的一层,是无状态的,下面的存储层才是核心,它叫 TiKV。
TiKV 如何存储数据
TiKV 官方原理图如下:
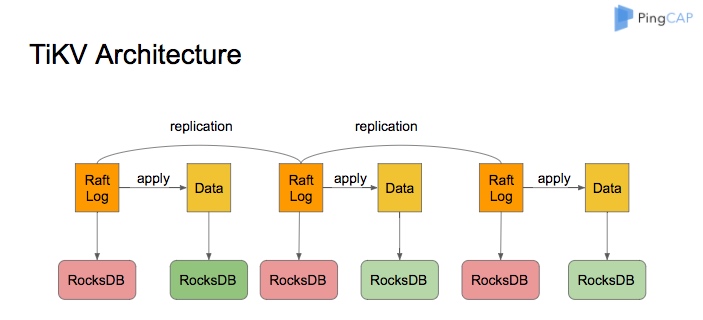
TiKV 是 TiDB 的核心组件,一致性和事务隔离都是基于它的能力得以实现的,其官方原理图如图 10-2 所示。每个 TiKV 拥有两个独立的 RocksDB 实例,一个用于存储 Raft Log,另一个用于存储用户数据和多版本隔离数据(基于key+版本号实现),从这里可以看出,TiDB 的存储存在大量冗余,所以 TiDB 的测试性能才会如此的高,符合空间换时间的基本原理。
和 TiKV 并列的还有一个 TiFlash 列存储引擎,是为了 OLAP 在线数据分析用的,我们在此不做详细讨论。
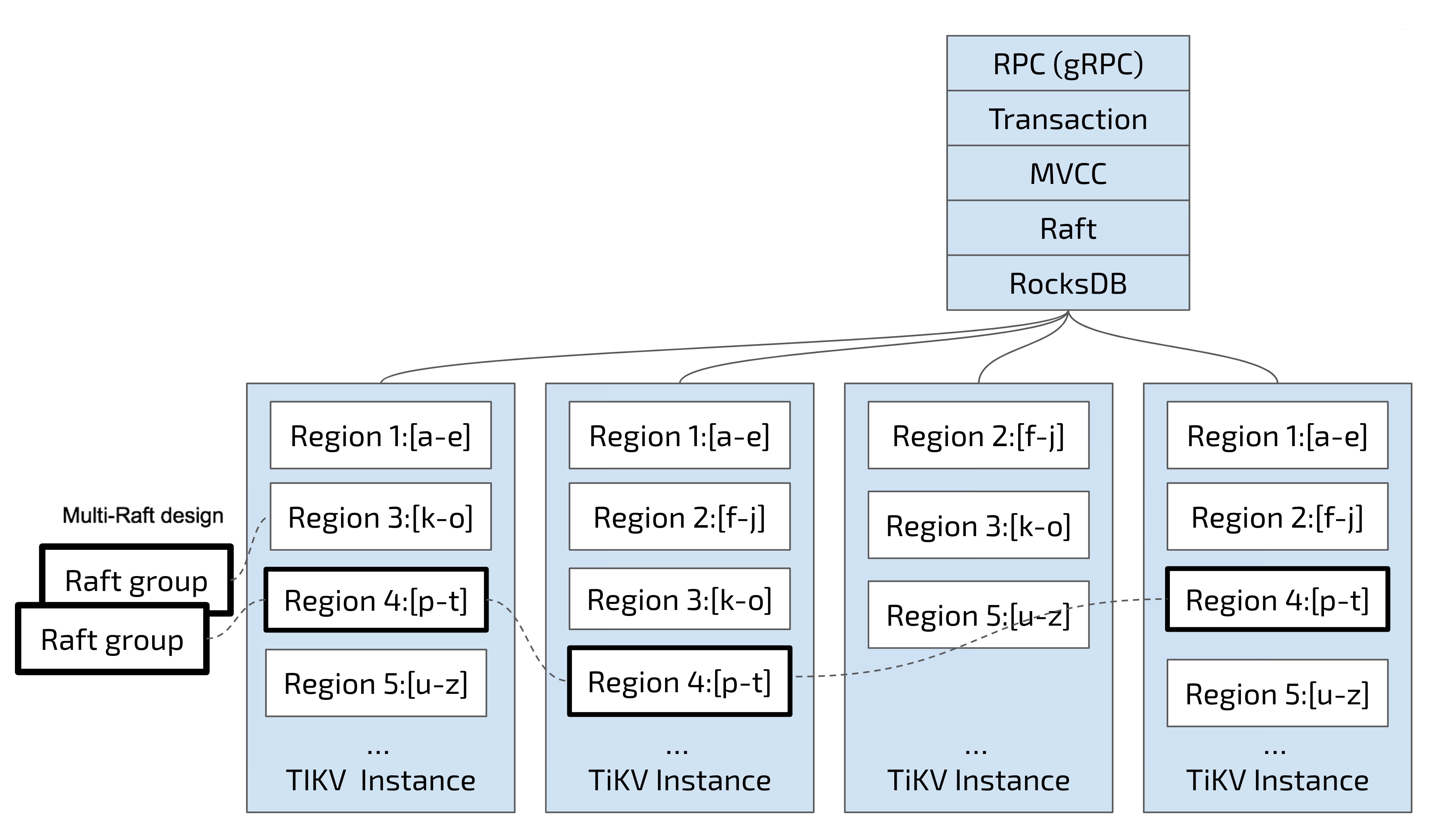
除此之外,TiKV 还发明了一层虚拟的“分片”(Region),将数据切分成 96MB~144MB 的多个分片,并且用 Raft 算法将其分散到多个节点上存储。注意,在 TiKV 内部存储用户数据的那个 RocksDB 内部,多个分片是致密存储的,分片之间并没有逻辑关系。TiKV 数据分片的架构如图 10-3 所示。
由于 TiDB 的设计风格比较狂野,所以不兼容的部分比较多,如图 10-4 所示。

TiDB 对 CAP 和不可能三角的抉择
TiDB 放弃了新不可能三角中的事务隔离,和 Spanner 一样放弃了 CAP 理论中的“完全可用性”:一旦出现脑裂,就会出现意外的返回结果(如超时),因为 TiDB 选择了保证一致性:如果无法达到数据强一致,就要停止服务。
一句话概括 TiDB:①搭建在 KV 数据库集群之上的,②兼容部分 MySQL 语法的,③有一些事务处理能力的高性能数据库。
阅读数:188
字数:621
最后更新:2026-05-17 22:51:25