小型机的优势,x86 的劣势:I/O 性能
《性能之殇》中提到了 x86 的 I/O 性能被架构锁死的问题。相比之下,小型机的 I/O 性能上限非常高,甚至可以为存储子系统配置专门的 CPU。
如今,海量廉价的 x86 服务器集群在越来越快的网卡速率的支持下,在系统总容量和可用性方面已经超过了小型机,使得小型机只能在特定规模和行业的业务中保持优势。然而,I/O 性能不足一直是 x86 的弱点,直到最近两年才有所改善。
突飞猛进的 PCIe
近年来,已经使用了十年的 PCIe 3.0 突然开始迅速升级,以每年一代的速度推进,每次带宽都能翻倍,看起来进步很大。然而,当我们把目光从惊人的 128GB/s(PCIe 5.0 x32)的数字上移开,仔细观察一块主板上同时存在的 5.0、4.0 和 3.0 插槽时,会发现一个更令人惊讶的事实:4.0 和 5.0 是在基础电气属性不变、金手指数量完全保持不变的情况下,通过重定时器和重驱动器组件实现通信频率两次翻倍,“强上陆地神仙”的结果。此外,5.0 插槽就是 5.0 插槽,不能拆分成两个 4.0 插槽使用。如果想插入 4.0 设备,可以,但只能插入一个:因为从 4.0 到 5.0 并不是水管变粗了,而是水管支持的流速提高了,这对接收端设备的容错能力提出了更高的要求。
为什么英特尔一屁股坐到 PCIe 牙膏上了呢?因为下一代超级 I/O 架构:CXL 需要基于 PCIe 5.0 来实现。
全村的希望 CXL
2022 年 11 月,首款支持 CXL 的服务器 CPU(AMD EPYC 9004 系列)已经上市。尽管目前 CXL 技术的大规模应用尚未展开,但它已成为“全村的希望”。虽然英特尔直到 2019 年才推出了 CXL 标准,但它不仅在短短三年内推动了业界推出兼容 CXL 技术的 CPU(而且是友商开发的),还吸纳了两个竞争对手——OpenCAPI 联盟和 Gen-Z 联盟。CXL 成为了唯一的“新一代通用 I/O 标准”。
凭什么呢?就凭 CXL 是英特尔向业界投放的一颗重磅炸弹:一次性开放了从 CPU 直接驱动的 DDR 内存到 NVMe SSD 之间广阔的“无人地带”——基于 PCIe 5.0 技术,将 I/O 技术推向了一个新时代。别忘了,PCIe 协议也是由英特尔定义的。
内存、磁盘正在双向奔赴
近年来,随着 NVMe SSD 在服务器端的普及,内存和磁盘的性能边界正在变得逐渐模糊。十年前,SATA SSD 刚刚普及时,内存带宽和延迟为 100GB/S、60ns,而 SATA SSD 为 500MB/S、200μs,速度和延迟分别为1/200和3000倍;如今,内存和 PCIe 5.0 NVMe 磁盘的对比为 150GB/S、100ns 和 12.8GB/S、9μs,差距缩小至1/12和90倍。
CXL 补上了“存储器山”上 DDR 内存和 NVMe SSD 之间的巨大空隙

《CS:APP》第六章提出了著名的“存储器山”理论,如图 7-2 所示:离 CPU 越远的存储器容量更大延迟更高。去年发布的 AMD 9004 系列处理器引入了 12 通道的 DRAM 内存,对电路板设计和制造成本提出了非常高的要求,同时对 CPU 内部内存控制器的驱动能力也带来了挑战。基本可以确定内存条这个将一大块 DRAM 芯片在 Z 轴进行折叠以增加容量的技术已经走到尽头,未来将是 CXL 的时代。
CXL 提供了 I/O(设备发现、初始化、中断等基础功能)、缓存(低延迟数据复制)、内存(统一地址编码)三个模块,一次性解决了海量内存扩展和多级别缓存的需求。目前,支持 CXL 1.1 协议的扩展内存已经上市。
未来,双向奔赴的内存和磁盘将在 CXL 技术中胜利会师:容量和延迟分布将更加均匀,系统宏观性能将进一步提升。
CXL 三代技术发展的终极目标
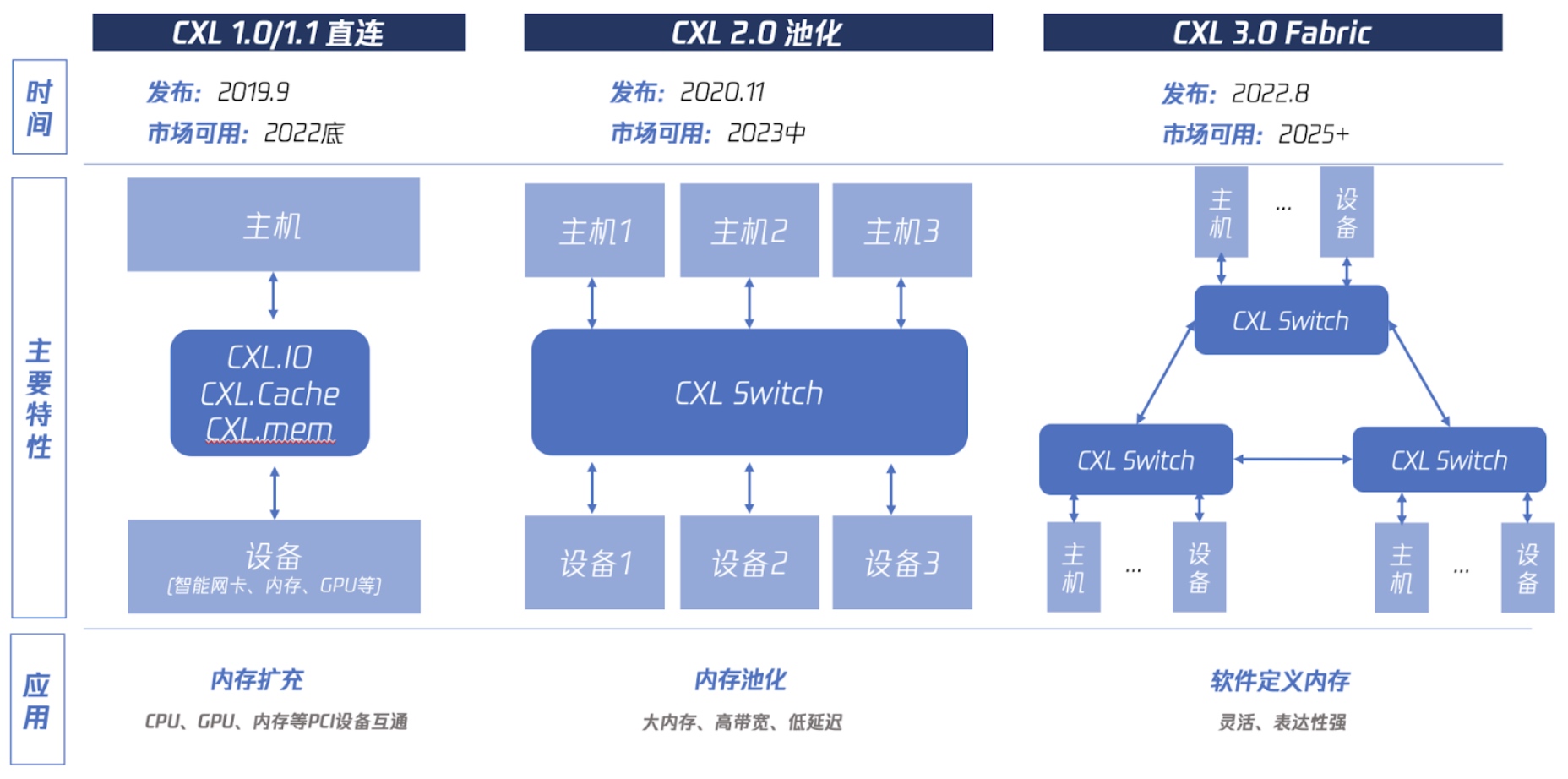
如图 7-3 所示,CXL 1.0 时代主要实现基本功能,2.0 要实现类似于 SAN 交换机技术的多对多内存池化,3.0 要构建 CXL 互联网络:实现软件定义内存集群。简单来说,就像分布式存储一样,用软件将内存集群化。
内存被软件集群化后,将给数据库架构带来巨大的改变:基于独立的 RDMA 网卡技术的计算与存储分离架构已经涌现出了如 Snowflake、Amazon Aurora、阿里云 PolarDB 等优秀的商用数据库产品。如果内存都能被集群化,那么“计算与存储分离”中的“计算”也将被颠覆。届时,“主从同步”四个字将拥有全新的意义。
超高速网卡也需要 CXL 来解决
当前,x86 服务器领域的各大厂商都在不遗余力地努力将 400G 网卡塞进服务器机箱。如果不考虑任何优化措施,仅依靠 Linux 网络栈运行 TCP 时只能达到 5Gbit/s,这主要是因为软件架构的滞后。然而,400G 网卡无法使用则是纯粹的硬件限制:400G 的带宽已经超出了八路内存的理论带宽上限,只要网卡数据仍然需要经过 CPU,并且仍然使用 DDR4/DDR5 内存,那么400G 网卡就是非常难以实现的。
CXL 技术为解决 400G 网卡的问题提供了一种解决方案:将网卡与 CPU 分离,使它们各自拥有独立的内存空间,并允许 CPU 无障碍地读写网卡芯片的内存空间。从本质上讲,这相当于重新定义了“网卡接收数据后将其存储到内存”这一过程中“内存”的含义。
这种思想其实我们已经有所了解:浮点运算能力远远超过 CPU 的 GPU,通过单独设计内存架构(称为显存),在其内部实现了卓越的性能,然后直接使用 DP 协议输出 8K 画面,而无需让大量数据经过 CPU 和内存,从而避免了性能瓶颈的出现。
大语言模型也需要 CXL 技术
最新的 65B 参数的大模型,如果使用 GPU 进行训练,将需要高达 192GB 的显存,而显存容量是目前 GPU 技术和成本的主要限制因素。借助 CXL 技术,未来的 GPU 将能够充分利用主板上常见的 4TB DDR5 内存,甚至可以使用 PCIe 5.0 12.8GB/s 的 SSD 磁盘进行训练,人均 650 亿参数大模型指日可待!