从读写分离到分布式
由于 Web 系统中读写需求拥有明显的二八分特征——读取流量占 80%,写入流量占 20%,所以如果我们能把读性能拆分到多台机器上,在同样的硬件水平下,数据库总 QPS 也就能提高五倍。
各种主从架构
各种主从架构是最简单最直接的读写分离架构。如图 9-1 所示就是阿里云 RDS 的几种主从架构。
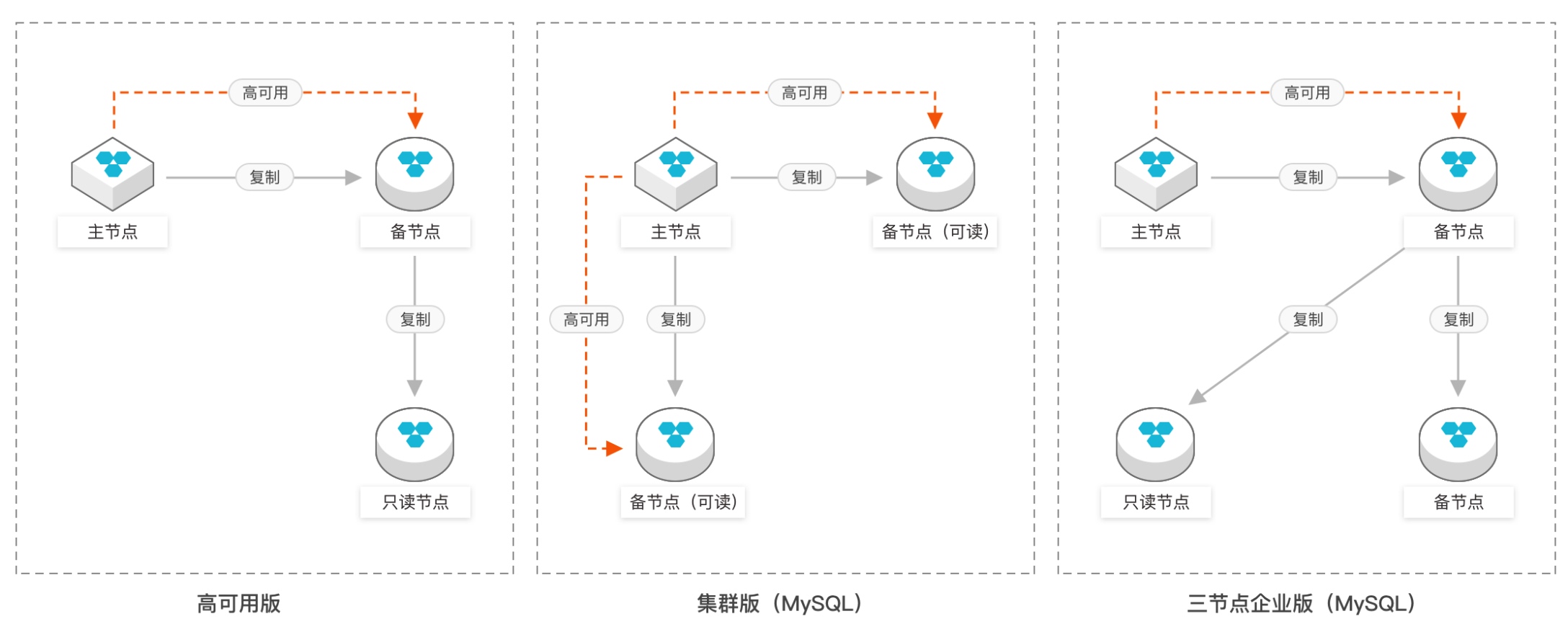
无论是远古时代谷歌的 MMM(Multi-Master Replication Manager for MySQL) 还是中古时代的 MySQL 官方的 MGR(MySQL Group Replication),还是最近刚刚完成开发且收费的官方 InnoDB Cluster,这些主从架构的实现方式都是一致的:基于行同步或者语句同步,近实时地从主节点向从节点同步新增和修改的数据。
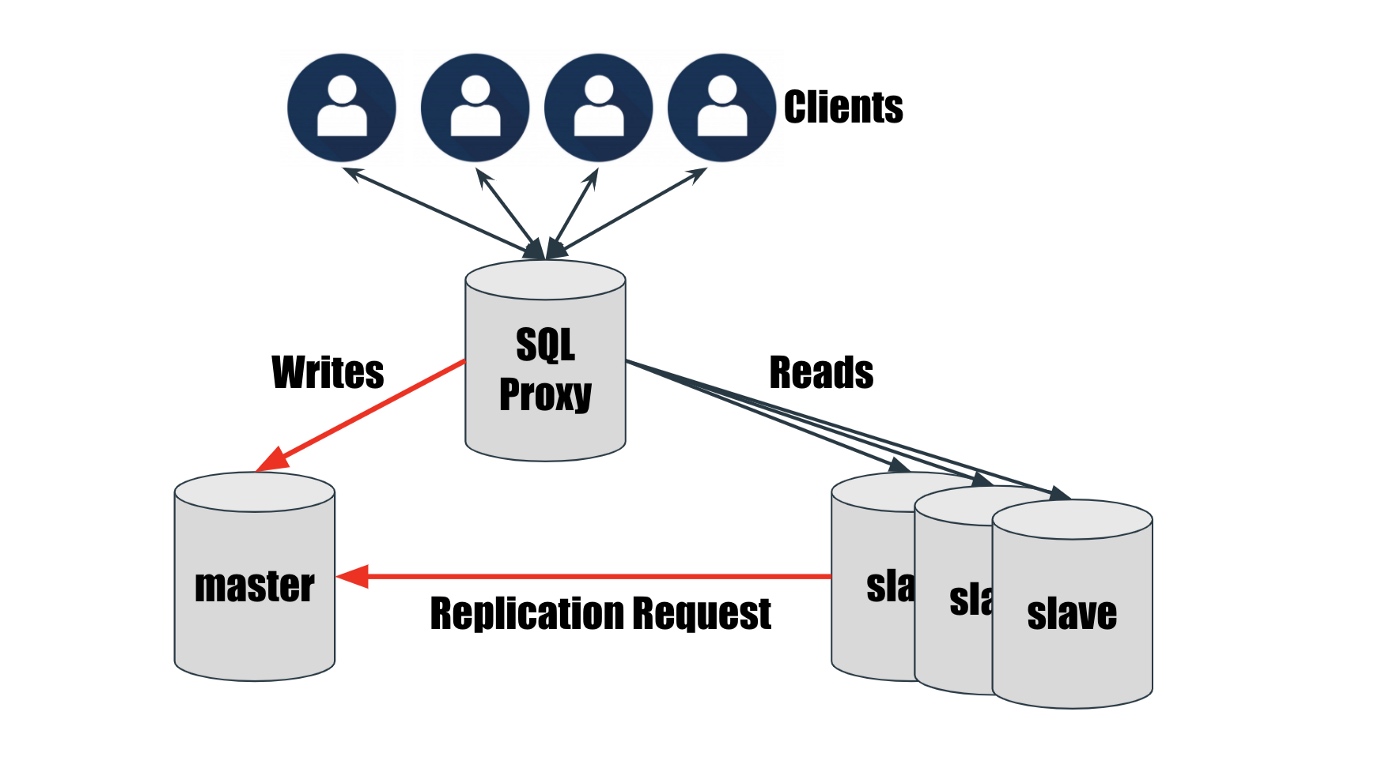
由于这种方法必然会让主从之间存在一段时间的延迟(数百毫秒到数秒),所以一般在主从节点前面还要加一个网关进行语句分发,其架构如图 9-2 所示。该集群的运行方式如下:
select等读语句默认发送到从节点,以尽量降低主节点负载- 一旦出现
update、insert等些语句,立刻发送到主节点 - 并且,本次会话(session)内的所有后续语句,必须全部发送给主节点,不然就会出现数据写入了但是读不到的情况
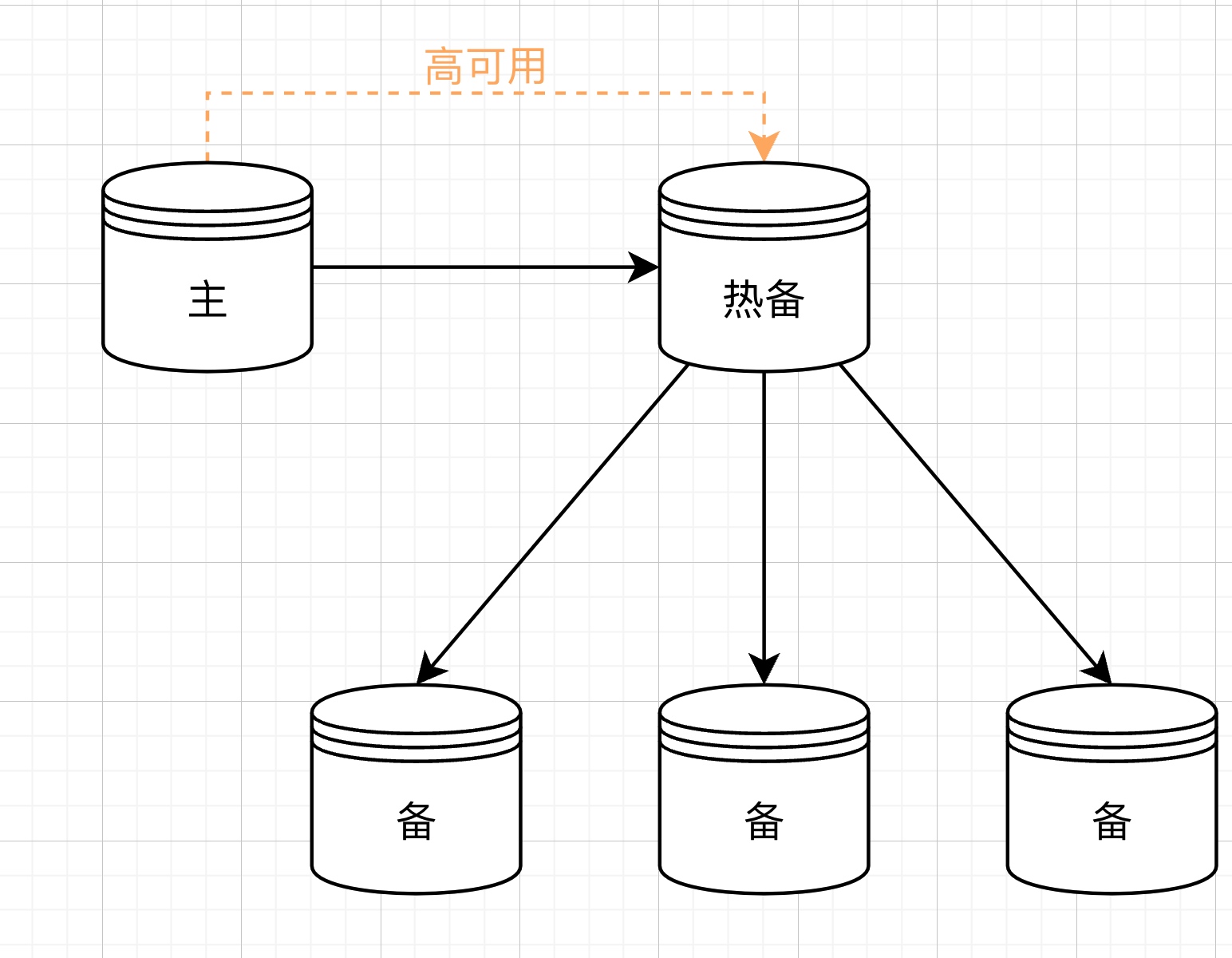
像图 9-3 那样搭建一个一主四从的 MySQL 集群,总 QPS 就能从单节点的 1 万提升到 5 万,顺便还能拥有主节点故障后高可用的能力。主从架构比较简单,也没有什么数据冲突问题,就是有一个很大的弱点:
写入性能无法提升:由于数据库承载的单点功能实在是太多了(自增、时间先后、事务),导致哪怕架构玩出了花,能写入数据的节点还是只能有一个,所有这些架构都只能提升读性能。
那怎么提升写性能呢?这个时候就要拿出分布式数据库了。
分布式数据库
由于数据库的单点性非常强,所以在谷歌搞出 GFS、MapReduce、Bigtable 三驾马车之前,业界对于高性能数据库的主要解决方案是买 IOE 套件:IBM 小型机 + Oracle 数据库 + EMC 商业存储。而当时的需求也确实更加适合使用商用解决方案。
后来搜索引擎成为了第一代全民网站,而搜索引擎的数据库却“不那么关系型”,所以谷歌搞出了自己的分布式 KV 数据库。后来谷歌发现 SQL 和事务隔离在很多情况下还是刚需,于是在 KV 层之上改了一个强一致支持事务隔离的 Spanner 分布式数据库。而随着云计算的兴起,分布式数据库已经成了云上的“刚需”:业务系统全部上云,总不能还用 Oracle 物理服务器吧?于是云上数据库又开始大踏步发展起来。
下面我们按照时间顺序,逐一梳理分布式数据库的发展史。