InnoDB 数据插入测试
接下来,我们将对 InnoDB 进行一次数据插入测试,以揭示其索引页“再平衡”的具体操作,追踪索引扩层的具体动作,确定id|页号中页号的数据长度,并解决“2000w 行是否该分表”这个历史悬案。
神奇的“2000W 行分表”历史悬案
相信大家都听说过“单表到了 2000 万行就需要分表了”,甚至有人还看过“京东云开发者”的那篇著名的文章,但是那篇文章为了硬凑 2000 万搞出了很多不合理的猜想。
下面我们实际测试一下 MySQL 8.0.28 运行在 CentOS Stream release 9 上(文件系统为 ext4),索引层数和数据行数之间的关系,相信测试完以后,你会对这个问题有深刻的理解。
测试准备
测试表结构如代码清单 8-1 所示。
CREATE TABLE `index_tree` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`s1` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's1',
`s2` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's2',
`s3` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's3',
`s4` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's4',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;我们采用不可变长度的 char 来进行测试,根据 MySQL 8.0 关于 CHAR 和 VARCHAR 类型的官方文档,当我们只保存s1这种 ASCII 字符时,一行数据的长度很容易就可以计算出来:4 + 255 + 255 + 255 + 255 = 1024 字节
ibd 结构探测工具
我们采用阿里巴巴开源的MySQL InnoDB Java Reader来窥探 ibd 内部所有页的情况,主要是看它们的层级。
开始插入数据
在只插入了一行数据时,表数据如图 8-5 所示,此时的 MySQL InnoDB Java Reader 结果如代码清单 8-2 所示。
=====page number, page type, other info=====
0,FILE_SPACE_HEADER,space=1289,numPagesUsed=5,size=7,xdes.size=1
1,IBUF_BITMAP
2,INODE,inode.size=4
3,SDI
4,INDEX,root.page=true,index.id=4605,level=0,numOfRecs=1,num.dir.slot=2,garbage.space=0
5,ALLOCATED
6,ALLOCATED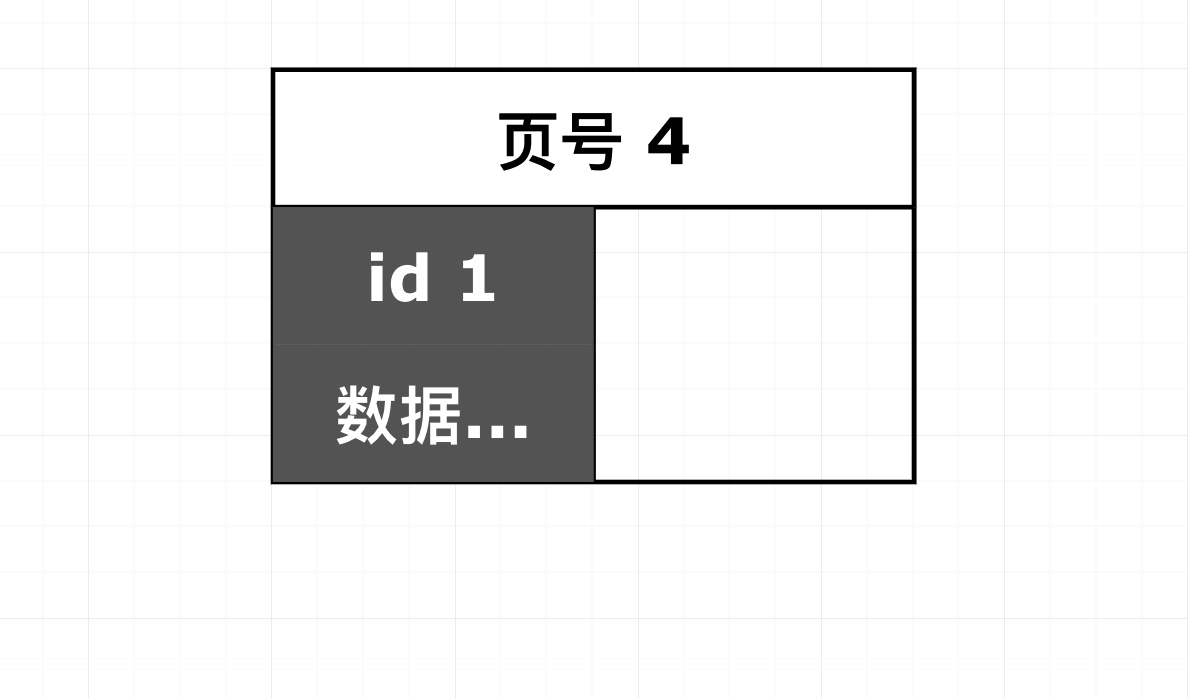
可以看出,只有一行数据时,ibd 文件内部只有一个页,此时的页结构如图 8-6 所示,index_tree.ibd文件的大小为 112KB。
1. 首次索引分级
我们继续插入数据,在插入了第 15 行后,这个 idb 文件从 1 页分裂成了 3 页,此时的 MySQL InnoDB Java Reader 结果如代码清单 8-3 所示。
=====page number, page type, other info=====
0,FILE_SPACE_HEADER,space=1289,numPagesUsed=7,size=8,xdes.size=1
1,IBUF_BITMAP
2,INODE,inode.size=4
3,SDI
4,INDEX,root.page=true,index.id=4605,level=1,numOfRecs=2,num.dir.slot=2,garbage.space=0
5,INDEX,index.id=4605,level=0,numOfRecs=7,num.dir.slot=3,garbage.space=7350
6,INDEX,index.id=4605,level=0,numOfRecs=8,num.dir.slot=3,garbage.space=0
7,ALLOCATED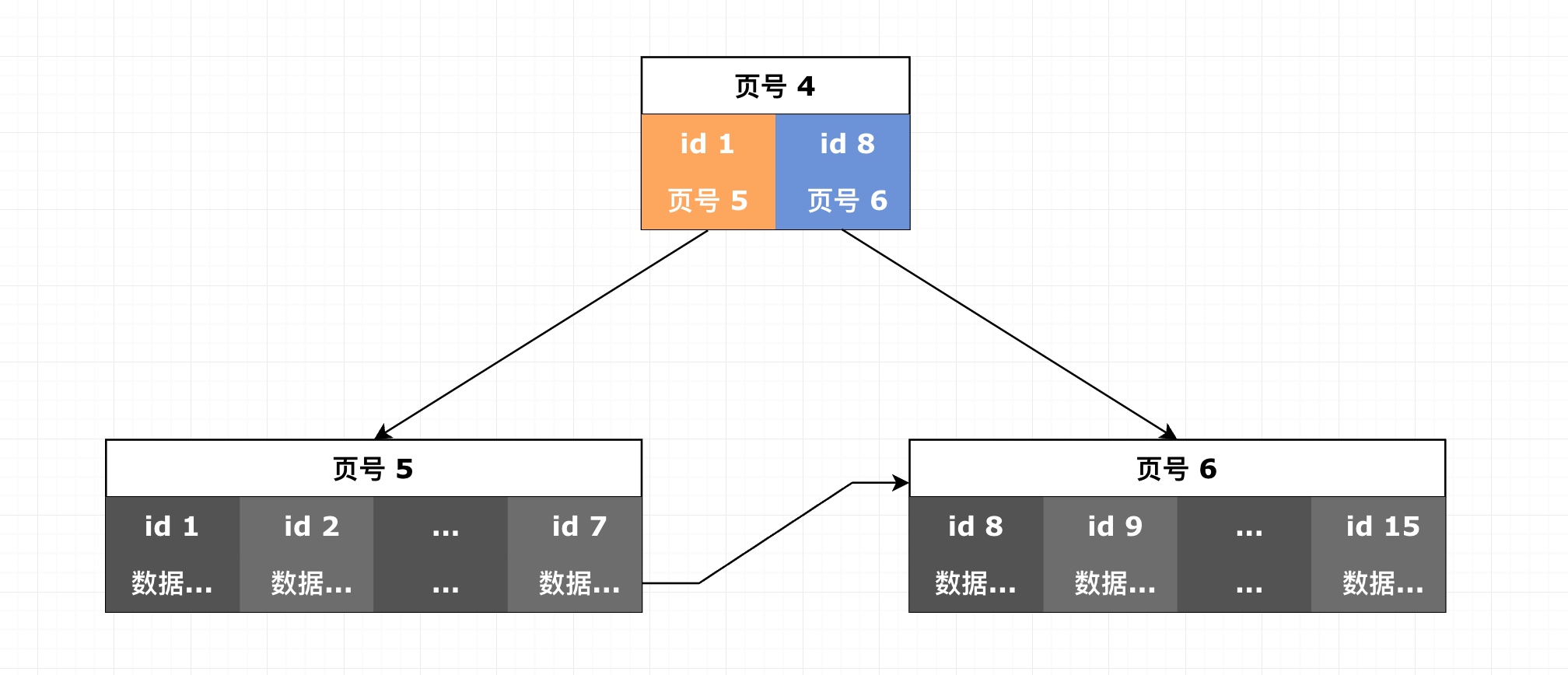
我们能够看出,本来这 14 条数据都是在初始的那个 4 号页内部储存的,即数据部分至少有1024*14=14KB的容量,在插入第 15 条数据迈向 15KB 的时候,innodb 发了页的分级:B+ 树分出了两级,顶部为一个索引页 4,底部为两个数据页 5 和 6,5 号页拥有 7 行数据,6 号页拥有 8 行数据。此时的页结构如图 8-7 所示。
这个转变说明每一页可用的数据容量为14kB - 15KB之间。而且,从garbage.space可以看出,5 号页是之前那个唯一的 4 号页,而新的 4 号页和 6 号页则是本次分级的时候新建的。
下面让我们继续插入数据,看它什么时候能从二层增长为三层。
2. 二层转换为三层
以 500 为步长批量插入数据,在 16500 行的时候,还是二层,此时的 MySQL InnoDB Java Reader 结果如代码清单 8-4 所示。
=====page number, page type, other info=====
0,FILE_SPACE_HEADER,space=1292,numPagesUsed=37,size=1664,xdes.size=22
1,IBUF_BITMAP
2,INODE,inode.size=4
3,SDI
4,INDEX,root.page=true,index.id=4608,level=1,numOfRecs=1180,num.dir.slot=296,garbage.space=0
5,INDEX,index.id=4608,level=0,numOfRecs=7,num.dir.slot=3,garbage.space=7350
6,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0
7,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0
8,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0
9,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0但是当表长度来到 17000 的时候,已经是三层了,此时的 MySQL InnoDB Java Reader 结果如代码清单 8-5 所示。
=====page number, page type, other info=====
0,FILE_SPACE_HEADER,space=1292,numPagesUsed=39,size=1728,xdes.size=22
1,IBUF_BITMAP
2,INODE,inode.size=4
3,SDI
4,INDEX,root.page=true,index.id=4608,level=2,numOfRecs=2,num.dir.slot=2,garbage.space=0
5,INDEX,index.id=4608,level=0,numOfRecs=7,num.dir.slot=3,garbage.space=7350
6,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0
7,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0
... ...
36,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0
37,INDEX,index.id=4608,level=1,numOfRecs=601,num.dir.slot=152,garbage.space=7826
38,INDEX,index.id=4608,level=1,numOfRecs=614,num.dir.slot=154,garbage.space=0
39,ALLOCATED
40,ALLOCATED
... ...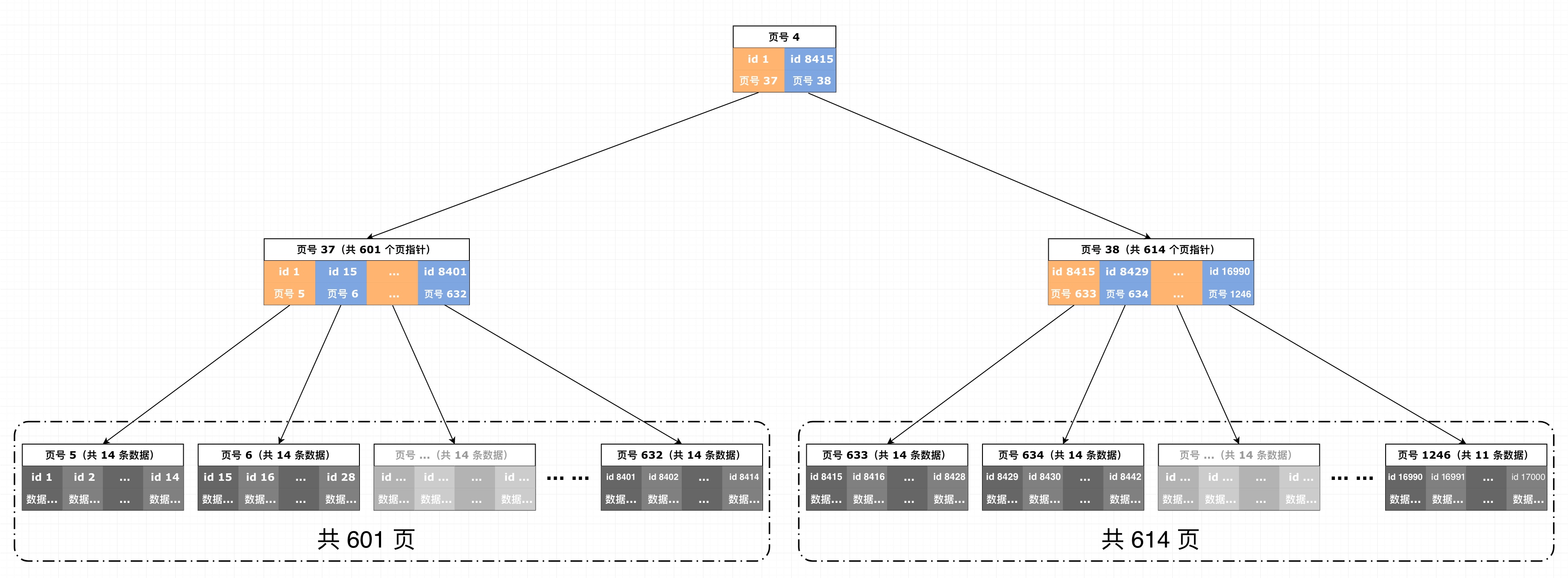
在 17000 行时,InnoDB 的索引页变成了 3 层,此时的页结构如图 8-7 所示,index_tree.ibd文件的尺寸为 27MB。
在整颗 B+ 树从二层转换为三层的过程中,只修改了三个页:
- 将目前唯一的索引页 4 号的数据复制到 37 号页中,level 保持不变(此时 37-63 号已经被提前
ALLOCATED出来用作备用页了) - 将 38 号页初始化成一个新的 level=1 的索引页,并将左侧 37 号页右边一半的页指针转移给 38 号页,再删除 37 号页中的原指针
- 重新初始化 4 号页,设置为顶层(level=2)索引页,创建两个页指针:第一个指向 37,第二个指向 38
为什么是 17000 行呢?我们来计算一下二层索引的极限容量:
- 已知一个最底层(level=0)的数据节点可以存储 14 条数据
- 假设索引页内部的一个页指针的长度是
4+8=12字节,那 2 层索引的极限就是:
(14 * 1024 / 12) * 14 = 16725.33和实测值完美契合!
此时计算可知,一个索引页至少可以存储14 * 1024 / 12=1194.66666666个页指针。
3. 三层转换为四层
继续向 index_tree 表中批量插入数据,在数据继续分层之前,整棵树的结构保持不变,只是会不断增加 level=0 和 level=1 的页的数量。
但当行数来到了 21427000 行时,索引就从 3 层转换为了 4 层了,此时磁盘 ibd 文件为 24GB,此时的 MySQL InnoDB Java Reader 结果如代码清单 8-6 所示。
=====page number, page type, other info=====
0,FILE_SPACE_HEADER,space=1292,numPagesUsed=4,size=1548032,xdes.size=256
1,IBUF_BITMAP
2,INODE,inode.size=4
3,SDI
4,INDEX,root.page=true,index.id=4608,level=3,numOfRecs=2,num.dir.slot=2,garbage.space=0
5,INDEX,index.id=4608,level=0,numOfRecs=7,num.dir.slot=3,garbage.space=7350
6,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0
... ...
1424021,INDEX,index.id=4608,level=2,numOfRecs=601,num.dir.slot=152,garbage.space=7826
1424022,INDEX,index.id=4608,level=2,numOfRecs=672,num.dir.slot=169,garbage.space=0
... ...由此可知,索引结构是这样的:
- 1 个 4 层(level=3)索引页,含有 2 个 3 层索引页的指针
- 2 个 3 层(level=2)索引页,其中左侧的 1424021 号页有 601 个底层数据页的指针,右侧的 1424022 号页有 672 个底层数据页的指针
601+672=1273个 2 层索引页,每页含有 1194+ 个底层数据页的指针21427000/14=1530500个底层数据页,每页含有 14 条数据
转换的过程中,哪些页需要更新数据呢?还是只需要修改三个页:
- 需要将 4 号页(旧顶层页)的数据拷贝到 1424021 号页(新 level=2 左)中
- 新生成 1424022 号页(新 level=2 右),将 1424021 号页(新 level=2 左)内部右侧的 672 个页指针(
id|页号)复制到 1424022 号页中,并删除 1424021 号页中的原指针 - 重新初始化 4 号页,创建两个页指针:第一个指向 1424021,第二个指向 1424022
再增加一层需要再插入 1200 倍的数据,笔者就不测试了,有条件的读者可以自己尝试。
计算页指针id|页号的大小
无论是中文技术文章还是英文技术文章,笔者甚至还查了 MySQL 8.0 InnoDB 的官方文档,并没有说“页号”的大小,甚至对于id的大小都没有一个统一的说法。下面我们尝试自己算出来:
- 在 14-15 之间一层索引转换成了二层索引,所以页可用容量最大值
1024 * 15 = 15360 - 最小值
1024 * 14 = 14336 - 在 16500-17000 之间二层索引转换成了三层索引,对应的索引数最大值为
17000 / 14 = 1214.28 - 索引数最小值为
16500 / 14 = 1178.57
我们拿最大值除以最小值,得到 15360 / 1178.57 = 13.03字节,拿最小值除以最大值,得到 14336 / 1214.28 = 11.81字节,所以我们可以得出结论:
单个id|页号的大小应该为 12 字节或者 13 字节
接下来怎么确定呢?再拿 bigint 做一遍测试就行了。
利用 bigint 确定页号的大小
我们创建一个名为index_tree_bigint的表,其结构如代码清单 8-7 所示。
CREATE TABLE `index_tree_bigint` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`s1` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's1',
`s2` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's2',
`s3` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's3',
`s4` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's4',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;单行数据的容量从 1024 字节增加到了 1028 字节。
按照同样的流程进行测试,可以发现还是 14 到 15 条的时候发生的一层转换到两层,从 12500 到 13000 条时从二层转换到了三层,我们使用同样的方法进行计算:
1028 * 15 / ( 12500 / 14 ) = 17.271028 * 14 / ( 13000 / 14 ) = 15.50
主键采用 bigint 类型时,单个id|页号的大小应该为 16 字节或者 17 字节。
得出结论:“页号”为 8 字节
由于页号采用奇数长度的概率非常低,我们可以得出一个十分可信的结论:在 MySQL 8 中,id 的长度和类型有关:int为 4 字节,bigint为 8 字节,“页号”的长度为 8 字节。所以,单个id|页号的大小应该为 12 字节或者 16 字节。