第一代分布式数据库:中间件
朴素的中间件其实就是第一代分布式数据库。
在 MySQL 体系内演进
关系型数据库为了解决不可能三角需求,其基本架构 40 年没有变过。
MySQL 自己其实已经是一个非常优秀的满足互联网业务场景的单体数据库了,所以基于 MySQL 的基本逻辑进行架构改进,是最稳妥的方案。
在没有分布式关系型数据库技术出现的时代,后端开发者们往往只能选择唯一的刀耕火种的路:在应用代码里调用多个数据库,以应对单个数据库性能不足的困境。后来,有人把这些调用多个数据的代码抽出来作为单独的一层,称作数据库中间件。
数据库中间件
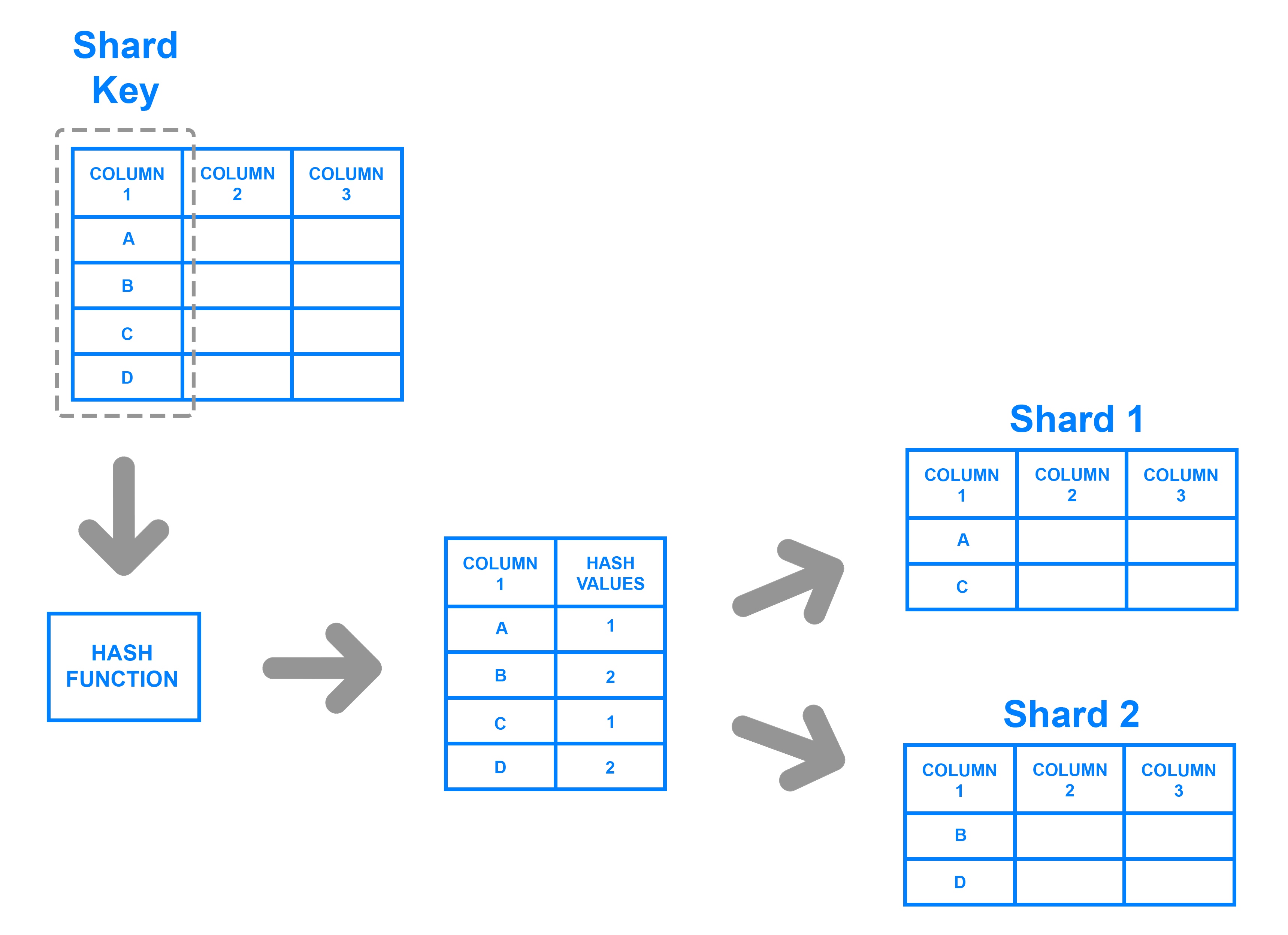
首先,对数据表进行纵向分表:按照一定规则,将一张超多行数的表分散到多个数据库中,如图 9-4 所示。
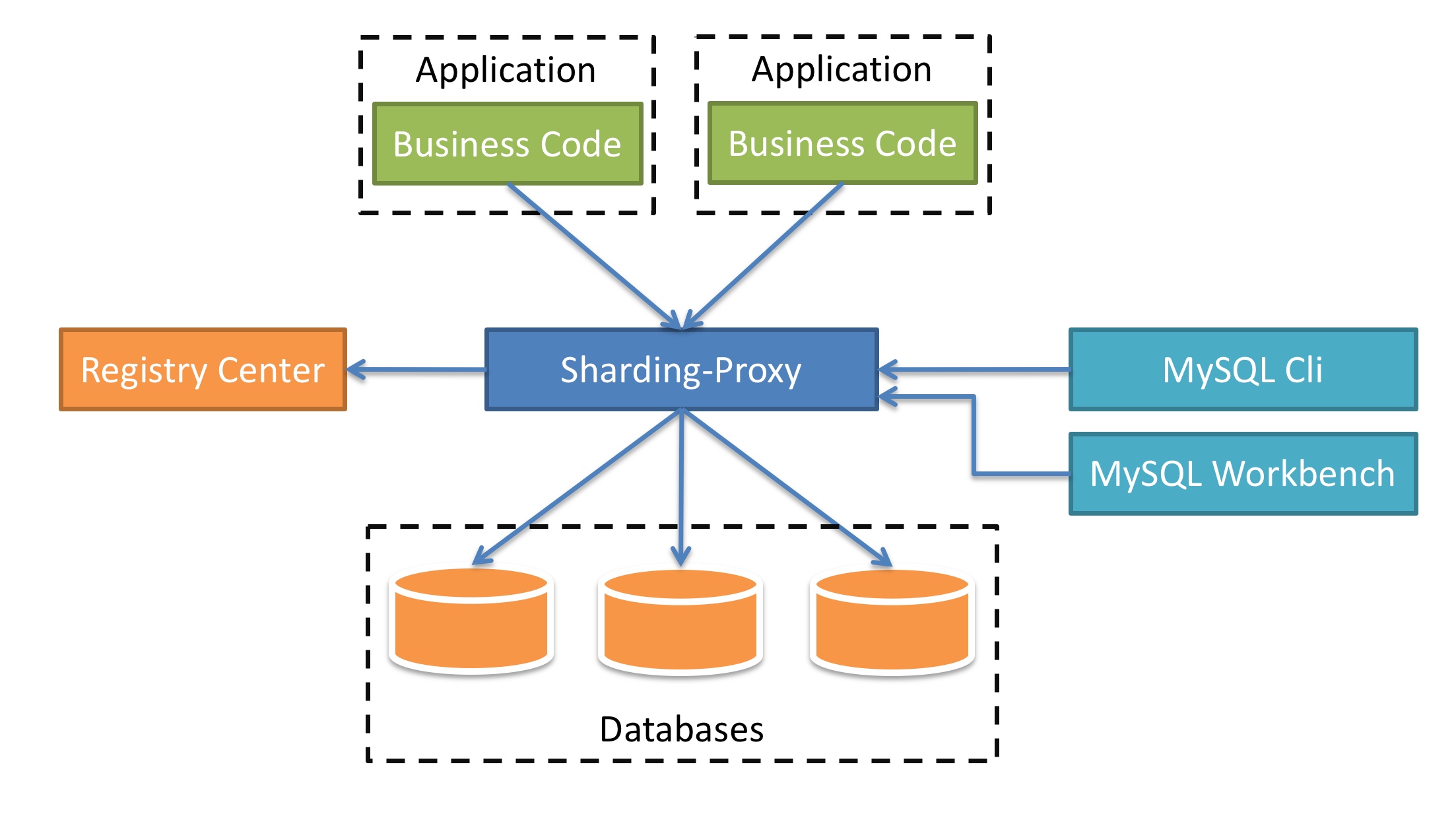
然后,无论是插入、更新还是查询,都通过一个代理(Proxy)将 SQL 进行重定向和拆分,发送给多个数据库,再将结果聚合,返回。如图 9-5 所示就是 ShardingSphere 中的 Sharding-Proxy 工作方式。
大名鼎鼎的数据库中间件,其基本原理一句话就能描述:使用一个常驻内存的进程,假装自己是个独立数据库,再提供全局唯一主键、跨分片查询、分布式事务等功能,将背后的多个数据库“包装”成一个逻辑上的单体数据库。
虽然“中间件”这个名字听起来像一个独立组件,但实际上它依然是强业务亲和性的:没有几家公司会自己研发数据库,但每家公司都会研发自己的所谓中间件,因为中间件基本上就代表了其背后的一整套“多数据库分库分表开发规范”。所以,中间件也不属于“通用数据库”范畴,在宏观架构层面,它依然属于应用的一部分。笔者称呼这个时代为刀耕火种时代。
那该怎么脱离刀耕火种呢?人类的大脑是相似的:既然应用代码做数据规划和逻辑判断很容易失控,那我们在数据库层面把这件事接管了行不行呢?当然可以,但是需要拿东西找信息之神交换。
历史上,第一个被放弃的是事务隔离,而它带来的就是第二代分布式数据库:KV 数据库。