内存缓存: Buffer Pool
在 MySQL 启动时,Buffer Pool 会向操作系统申请一片连续的内存空间,默认为 128MB,用作内存缓存。笔者强烈建议每台 MySQL 服务器根据自身机器资源情况,增大配置的内存值,这能十分显著地提升 MySQL 的性能。
缓存池大小
缓存池的大小由 innodb_buffer_pool_size 参数管理。通常建议设置为系统可用内存的 75%,但根据笔者的经验,对于普通的“冷热均衡”数据库,这个比例是合理的。但是对于热数据较少,却需要在短时间内(如几天)读写几乎所有表的全部数据的话,最好将比例设置在 50% 附近,否则运行一段时间后可能会爆内存(OOM 错误),MySQL 进程会被杀掉。
缓存池基本结构
缓存池与磁盘数据一样,分为一个个 16KB 的页进行管理。除了缓存索引页和数据页外,缓存池还包含 undo 页、插入缓存、自适应哈希索引和锁信息等。尽管缓存池已经在内存中,但它还需要一个额外的内存索引来保存每一页的表空间、页号、缓存页地址和链表节点信息,这个结构称为控制块。N 个控制块和 N 个 16KB 数据页连在一起,就构成了 Buffer Pool 占据的那一段连续内存,如图 8-9 所示。
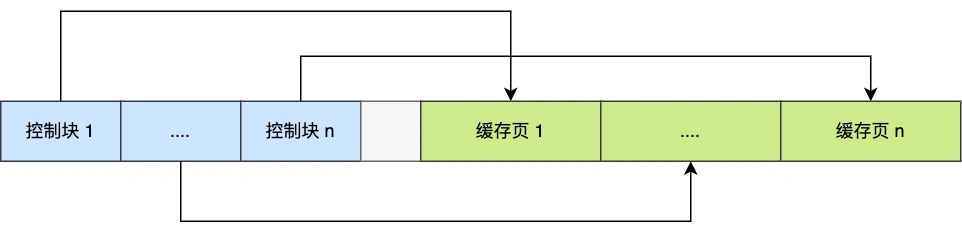
引入缓存池后的数据读写
缓存池中的 16KB 页与磁盘上的页一一对应,带来了读写两个方向的改变:
- 读取数据时,如果该页已在内存中,则无需再浪费一次磁盘 I/O。
- 写入数据时,数据会直接写入缓存中的页(不影响之后的读取),并在成功写入 redo log 后返回成功。同时,该页会被设置为脏页,等待后台进程将其真正写入磁盘。
缓存池 LRU 算法
除了控制块和数据页,Buffer Pool 中还存在着管理空闲页的free 链表和管理脏页的flush 链表,我们不再深入了解。
但是,管理缓存生命周期的 LRU 算法我们不能放过,必须狠狠地了解它一下。Buffer Pool 的 LRU 链表的数据结构如图 8-10 所示。
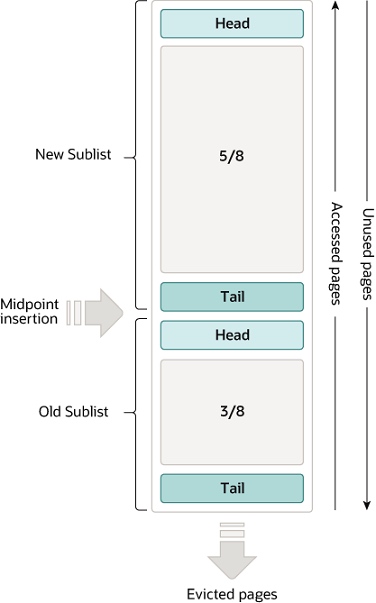
传统的 LRU 算法只用一个链表就实现了“移动至头部”和“淘汰尾部”两个操作,什么 InnoDB 非要搞一个变体呢?还是因为 B+ 树——由于底层数据的非连续性,导致 Buffer Pool 会遇到两个比较严重的问题:预读失效和缓冲池污染。
预读失效
预读失效很容易理解,因为预读本质上是基于局部性对需求的一种预估,正常的 SQL 并不能保证每一条取出的数据都是大概集中的,例如取性别为女的用户,在没有索引的情况下,就需要全表遍历,预读失效非常正常。
LRU 链表将数据分为新生代和老生代两个区域,分别占据5/8和3/8的内存空间,预读时只插入老生代的头部,同时老生代尾部元素会被淘汰。当数据真的被读取时,这一页会被立刻转移到新生代的头部,并且会挤出去一个新生代尾部的元素进入老生代的头部,数据还在缓存中。
不知道大家发现了没有,这个操作的本质是给 LRU 算法加了一层 LRU 算法,减小了缓存粒度。
缓冲池污染
由于磁盘数据库拥有极大的体量,相比之下内存容量却十分捉襟见肘,所以在用内存来做磁盘缓存时,一旦需求不满足局部性,缓存会被迅速劣化:当一条 SQL 需要扫描海量的数据页时,其它表用得好好的热数据突然就被别人清出内存了,结果就是磁盘 I/O 数量突然增加,系统崩溃。
于是 InnoDB 给“数据被读取时,该页会从老生代转移到新生代的头部”这个操作加了个条件:在老生代里面待的时间要足够久。
这里面有两个点非常巧妙:
- 改变的是“转移页操作”所需要的条件,而且这个条件(留存时间)的判断非常简单,只需要在加入老生代的时候增加一个时间戳就行,4 个字节,除此之外无需任何维护。
- 采用时间而不是次数来做限制,更加符合数据库的最终用户——人的真实需求。读取次数可能因为技术原因而增加,时间不会。没有无缘无故的爱,更没有无缘无故的读取。
Buffer Pool 应该怎么优化
- 内存配置的越大越好:多一倍的内存,比多一倍的 CPU 更能提高数据库性能。
- 减少对冷数据的随机调用:优化定时任务和队列的业务代码,避免这种情况。
- 在大批量执行 update 语句的时候,尽量自己控制事务:InnoDB 底层的数据隔离机制使得它的每一个写动作都是一个事务,所以如果你要在一次会话中写多行数据,最好自己控制事务,可以显著减少对缓冲池的影响以及磁盘 I/O 数量。
- 避免修改主键:修改主键的值会带来大量的数据移动,磁盘会不堪重负,缓存会疯狂失效。