B+ 树
B+ 树是 1970 年由 Rudolf Bayer 教授在《Organization and Maintenance of Large Ordered Indices》一文中提出的,此后迅速成为海量数据存储与检索的重要工具。以查询为主要场景的关系型数据库,无一例外地选择了 B+ 树。
B+ 树的基本思想
B+ 树是一种平衡多路查找树,其灵感源自平衡二叉树和 B 树,但专为速度较慢的“外存”设计,因此具有独特的设计方向:
尽量减少数据不断增长时的磁盘 I/O 数量,包括插入新数据场景和查询场景。
它将经典平衡二叉树的“再平衡”过程颠倒过来了——最底层的叶子节点紧密排列,新增数据时不断添加新的叶子节点,需要再平衡的不是叶子节点,而是上面的索引页。而索引页具有以下特点:
- 索引页数量少
- 再平衡时,B+ 树算法调整的索引节点数量也很少
- 索引容量足够大:3 层索引可承载 2000 万行数据,4 层索引可承载 200 多亿行
- 索引页少,可以将所有索引全部载入内存,读取索引的磁盘 I/O 趋近于 0
InnoDB 是如何组织数据的
下面我们来具体认识一下 InnoDB 中的索引和数据是怎么利用 B+ 树思想在磁盘上进行组织的。
1. 页
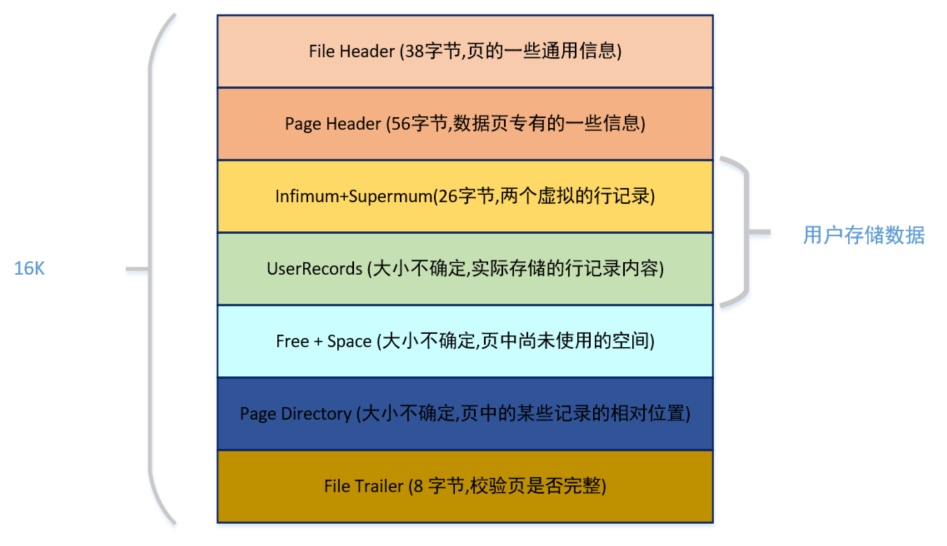
页是 MySQL 中数据存储的基本单元,整颗 B+ 树就是一个又一个相互使用指针连接在一起的页组成的。由于 InnoDB 出现的时候,SSD 还没有出现,所以它是为了机械磁盘及其 512 字节的扇区而设计的,所以页块的默认大小被设置为了 16KB(32 个连续扇区)。

图 8-1 展示出了页之间的指针关系:
- 上层页对下层页拥有
单向指针 - 同一层内相邻的页之间拥有
双向指针,无论是上面的索引页层还是底层的数据页层 - 最底层数据页层中,每一页可以存储多行数据,每一行数据拥有指向下一行的
单向指针
而在物理层面,每一页的内部结构都如图 8-2 所示。
2. 索引页里面有什么
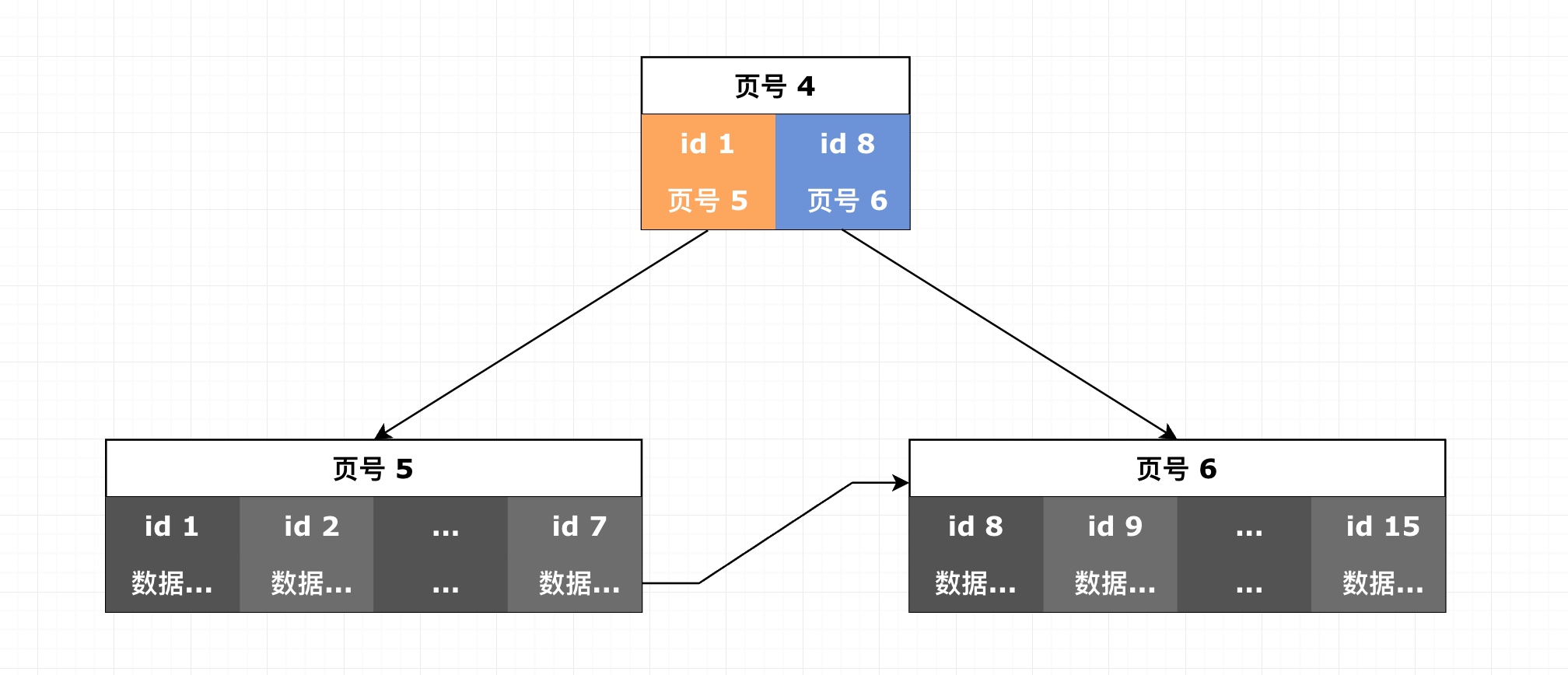
我们用更清晰的二层索引簇结构来展示索引页包含的关键信息,如图 8-3 所示。顶部那个彩色的页就是索引页。
除了头部和尾部的基础信息字段之外,索引页的“用户存储数据”紧密排列着指向下一层页的指针,结构为:id|页号。
这里的 id 就是这张表默认主键的那个 id,一般为int(4 字节)或者bigint(8 字节)。该数字的含义是:
该页号对应的页,以及下挂的所有页,所拥有的全部数据行中,id 最小的那行数据的 id。
InnoDB 使用这个数字可以快速定位某一行数据所处的页的位置。
页号就是页的编号,在不同版本的 MySQL 上这个页编号的长度是不一样的,下面我们会通过测试来确定 MySQL 8.0 中页编号的长度。
3. 数据页里面有什么
B+ 树上层的所有页只存储索引,只用最底层的页存储数据。这是 B+ 比 B 树优秀的地方:以一丢丢写入速度为代价,让较少的索引层数内存下了更多的索引指针,可以支撑海量的数据行数。
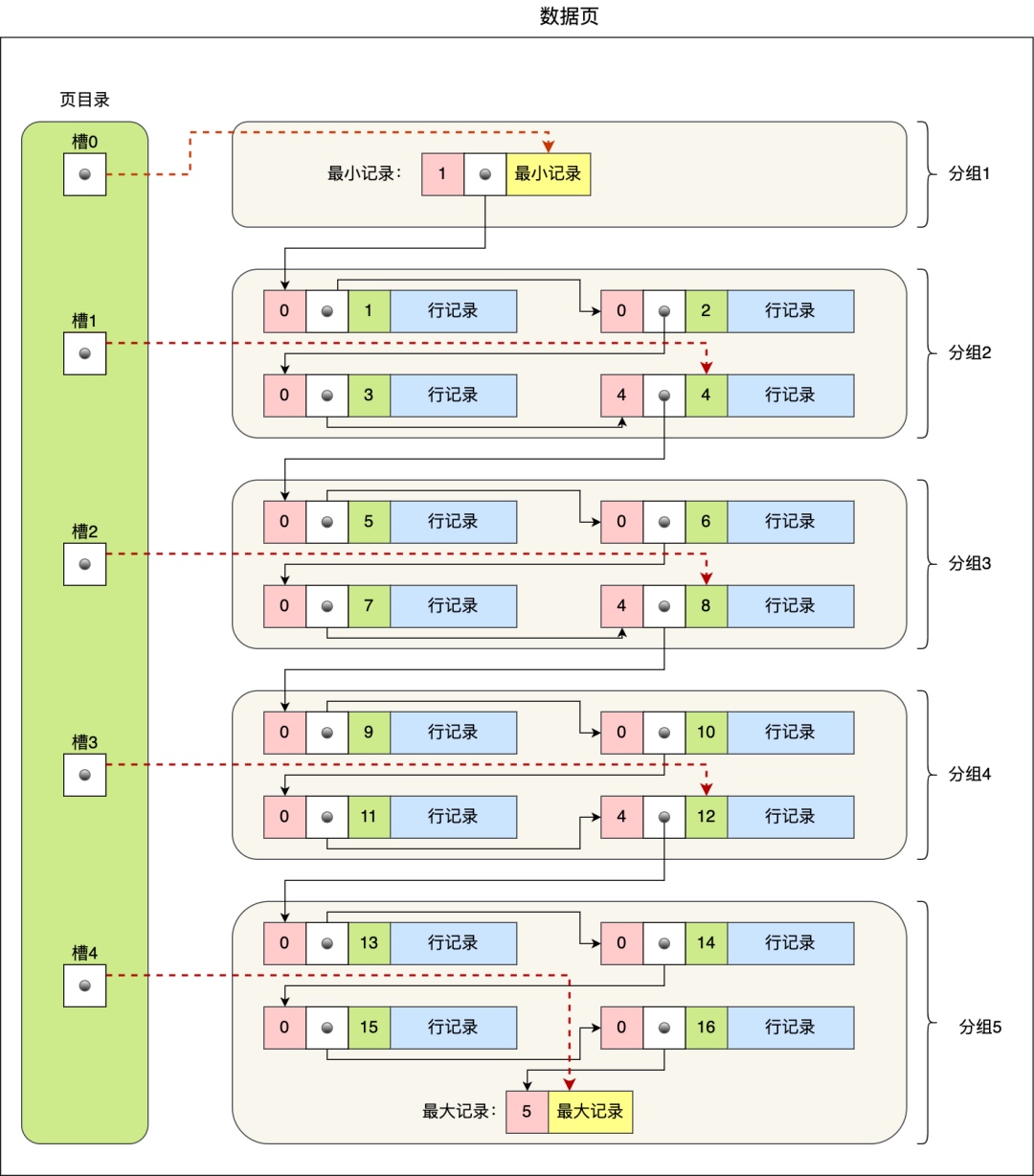
如图 8-4 所示,数据页内部是分槽的,相当于自己又加了一层索引。数据页内部拥有最小记录指针和最大纪录指针,有没有觉得一花一世界,数据页内部结构和 B+ 树颇有几分神似呢?
SQL 查询过程
有了前面的铺垫,真正的 SQL 查询过程就呼之欲出了。假设我们要找出id=6的一行数据,则我们执行的 SQL 为 select * from users where id=6。我们还怎么找出这一行数据呢?只需要逐层比对即可:
- 将顶部页(16KB)的数据读入内存,将 6 与每个
id|页号进行大小对比,找到 6 所在的页:大于等于当前 id 且小于右侧邻居的 id - 将上一步找到的那一页数据读入内存,重复上述比对操作,直到找到最底层的数据页
- 将数据页读入内存,找出
id=6索引下挂载的全部数据,这就是所需的这行数据