实战:利用 Go 语言的协程开发高性能爬虫
Go 语言的协程机制使其成为开发高性能爬虫的理想选择。通过利用外部 Redis 进行“协程间通信”,无论有多少 CPU 核心,Go 都能够充分利用它们。此外,编写 Go 代码也非常简单,无需自己管理进程和线程。然而,由于协程功能强大且代码简洁,调试成本较高:在编写协程代码时,笔者感觉自己像在炼丹,修改一个字符就能让程序从龟速提升到十万倍,简直比操控 ChatGPT 还神奇。
遵守法律法规和 robots.txt 业界规范
在编写爬虫之前,我们需要明确了解以下内容:从互联网上爬取内容需要遵守法律法规,并遵循 robots.txt 业界规范。关于 robots.txt 的具体规范内容,大家可以自行搜索相关资料。
笔者的开源项目
笔者开源了一个 Go 语言编写的开源互联网搜索引擎 DIYSearchEngine,遇到问题的读者可以参考我的代码。
爬虫工作流程
我们先设计一个可以落地的爬虫工作流程。
1. 设计一个 User-Agent (UA)
首先,我们需要为我们的爬虫设置一个 User-Agent。为了提高爬虫的成功率,我们可以选择较新的 PC 浏览器的 UA,并对其进行改造,以加入我们自己的项目名称。在笔者的项目中,项目名为“Enterprise Search Engine”,简称 ESE,因此笔者设定的 UA 是 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4280.67 Safari/537.36 ESESpider/1.0。你可以根据自己项目的需求进行相应的设定。
需要注意的是,有些网站会屏蔽非头部搜索引擎的爬虫,读者需要找到允许普通爬虫爬取的网站。
2. 选择一个爬虫工具库
笔者选择的爬虫工具库是 PuerkitoBio/goquery。它支持自定义 UA 爬取,并且可以对爬取到的 HTML 页面进行解析,从而获取非常重要的页面标题、页面中包含的超链接等信息。
3. 设计数据库
爬虫的数据库设计相对简单,只需要一个表即可。这个表中存储着页面的 URL、爬取到的标题以及网页的文字内容,具体的字段定义可以参考代码清单 3-1。
CREATE TABLE `pages` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`url` varchar(768) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '网页链接',
`host` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '域名',
`dic_done` tinyint DEFAULT '0' COMMENT '已拆分进词典',
`craw_done` tinyint NOT NULL DEFAULT '0' COMMENT '已爬',
`craw_time` timestamp NOT NULL DEFAULT '2001-01-01 00:00:00' COMMENT '爬取时刻',
`origin_title` varchar(2000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '上级页面超链接文字',
`referrer_id` int NOT NULL DEFAULT '0' COMMENT '上级页面ID',
`scheme` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT 'http/https',
`domain1` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '一级域名后缀',
`domain2` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '二级域名后缀',
`path` varchar(2000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT 'URL 路径',
`query` varchar(2000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT 'URL 查询参数',
`title` varchar(1000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '页面标题',
`text` longtext CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci COMMENT '页面文字',
`created_at` timestamp NOT NULL DEFAULT '2001-01-01 08:00:00' COMMENT '插入时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;4. 星星之火
爬虫具有一个非常强大的特性:自我增殖。由于每个网页通常都包含其他网页的链接,这使得我们可以通过这种方式实现无限扩展。为了启动爬虫,我们需要选择一个导航网站,并将该网站的链接手动添加到数据库中。读者可以根据个人喜好选择导航网站。笔者选择的是 hao123,此时我们需要将选定网站的首页链接插入 pages 表。
5. 运行爬虫
现在,让我们进入实际操作阶段。我们使用递归的思想实现自我增值,基本流程如下:
- 从数据库中读出一个没有爬过的页面链接
- 使用 curl 工具类获取网页文本
- 解析网页文本,提取出标题和页面中含有的超链接
- 将标题、一级域名后缀、URL 路径、插入时间等信息补充完全,更新到这一行数据上
- 将页面上的获取到的心得超链接插入 pages 表,第一次自我增殖完成!
爬虫代码可以参考代码清单 3-2 ,注释中解释了代码的逻辑。
func main() {
fmt.Println("My name is enterprise-search-engine!")
// 加载 .env
initENV() // 该函数的具体实现可以参考项目代码
// 开始爬
nextStep(time.Now())
// 阻塞,不跑爬虫时用于阻塞主线程
select {}
}
// 循环爬
func nextStep(startTime time.Time) {
// 初始化 gorm 数据库
dsn0 := os.Getenv("DB_USERNAME0") + ":" +
os.Getenv("DB_PASSWORD0") + "@(" +
os.Getenv("DB_HOST0") + ":" +
os.Getenv("DB_PORT0") + ")/" +
os.Getenv("DB_DATABASE0") + "?charset=utf8mb4&parseTime=True&loc=Local"
gormConfig := gorm.Config{}
db0, _ := gorm.Open(mysql.Open(dsn0), &gormConfig)
// 从数据库里取出本轮需要爬的 100 条 URL
var pagesArray []models.Page
db0.Table("pages").
Where("craw_done", 0).
Order("id").Limit(100).Find(&pagesArray)
tools.DD(pagesArray) // 打印结果
// 限于篇幅,下面用文字描述
1. 循环展开 pagesArray
2. 针对每一个 page,使用 curl 工具类获取网页文本
3. 解析网页文本,提取出标题和页面中含有的超链接
4. 将标题、一级域名后缀、URL 路径、插入时间等信息补充完全,更新到这一行数据上
5. 将页面上的超链接插入 pages 表,我们的网页库第一次扩充了!
fmt.Println("跑完一轮", time.Now().Unix()-startTime.Unix(), "秒")
nextStep(time.Now()) // 紧接着跑下一条
}当我们执行 go build -o ese *.go && ./ese 命令之后,得到的输出结果如代码清单 3-3 所示。
My name is enterprise-search-engine!
加载.env : /root/enterprise-search-engine/.env
APP_ENV: local
[[{1 0 https://www.hao123.com 0 0 2001-01-01 00:00:00 +0800 CST 2001-01-01 08:00:00 +0800 CST 0001-01-01 00:00:00 +0000 UTC}]]6. 合法合规:遵循 robots.txt 规范
为了确保爬虫的合法性和合规性,笔者选择了使用temoto/robotstxt库来检查我们的爬虫是否被允许爬取某个 URL。具体做法是,我们使用一张单独的表来存储每个域名的 robots 规则,并在 Redis 中建立缓存。每次在爬取 URL 之前,我们会先进行一次匹配操作,只有匹配成功的情况下才会进行爬取,以确保我们的爬虫行为符合业界规范的要求。
基础知识储备:Goroutine 协程
在开始之前,笔者假设你已经对 Go 协程有一定的了解。Go 协程是一种令人惊叹的技术,写起来特别像魔法。为了更好地理解协程,笔者想分享一个小技巧:当一个协程进入磁盘、网络等需要后台等待的任务时,它会将当前 CPU 核心(可以将其视为一个图灵机)的指令指针跳转到下一个协程的起始指令所在的指针位置。
需要注意的是,协程是一种特殊的并发形式。在并发函数中调用的函数必须都支持并发调用,类似于传统的“线程安全”,笔者称其为“协程安全”代码。如果你不小心编写了“协程不安全”的代码,可能会导致程序卡顿甚至崩溃。
使用协程并发爬取网页
为了利用多核 CPU 的全部计算资源,我们会一次取出一批需要爬的 URL,并使用协程并发爬取。
// tools.DD(pagesArray) // 打印结果
// 创建 channel 数组
chs := make([]chan int, len(pagesArray))
// 展开 pagesArray 数组
for k, v := range pagesArray {
// 存储 channel 指针
chs[k] = make(chan int)
// 启动协程
go craw(v, chs[k], k)
}
// 注意,下面的代码不可省略,否则你上面 go 出来的那些协程会瞬间退出
var results = make(map[int]int)
for _, ch := range chs {
// 神之一手,收集来自协程的返回数据,并 hold 主线程不瞬间退出
r := <-ch
_, prs := results[r]
if prs {
results[r] += 1
} else {
results[r] = 1
}
}
// 当代码执行到这里的时候,说明所有的协程都已经返回数据了
fmt.Println("跑完一轮", time.Now().Unix()-startTime.Unix(), "秒")我们的爬取函数 craw() 也需要进行协程化:
// 开始爬取,存储标题,内容,以及子链接
func craw(status models.Page, ch chan int, index int) {
// 调用 CURL 工具类爬到网页
doc, chVal := tools.Curl(status, ch)
// 对 doc 的处理在这里省略
// 最重要的一步,向 chennel 发送 int 值,该动作是协程结束的标志
ch <- chVal
return
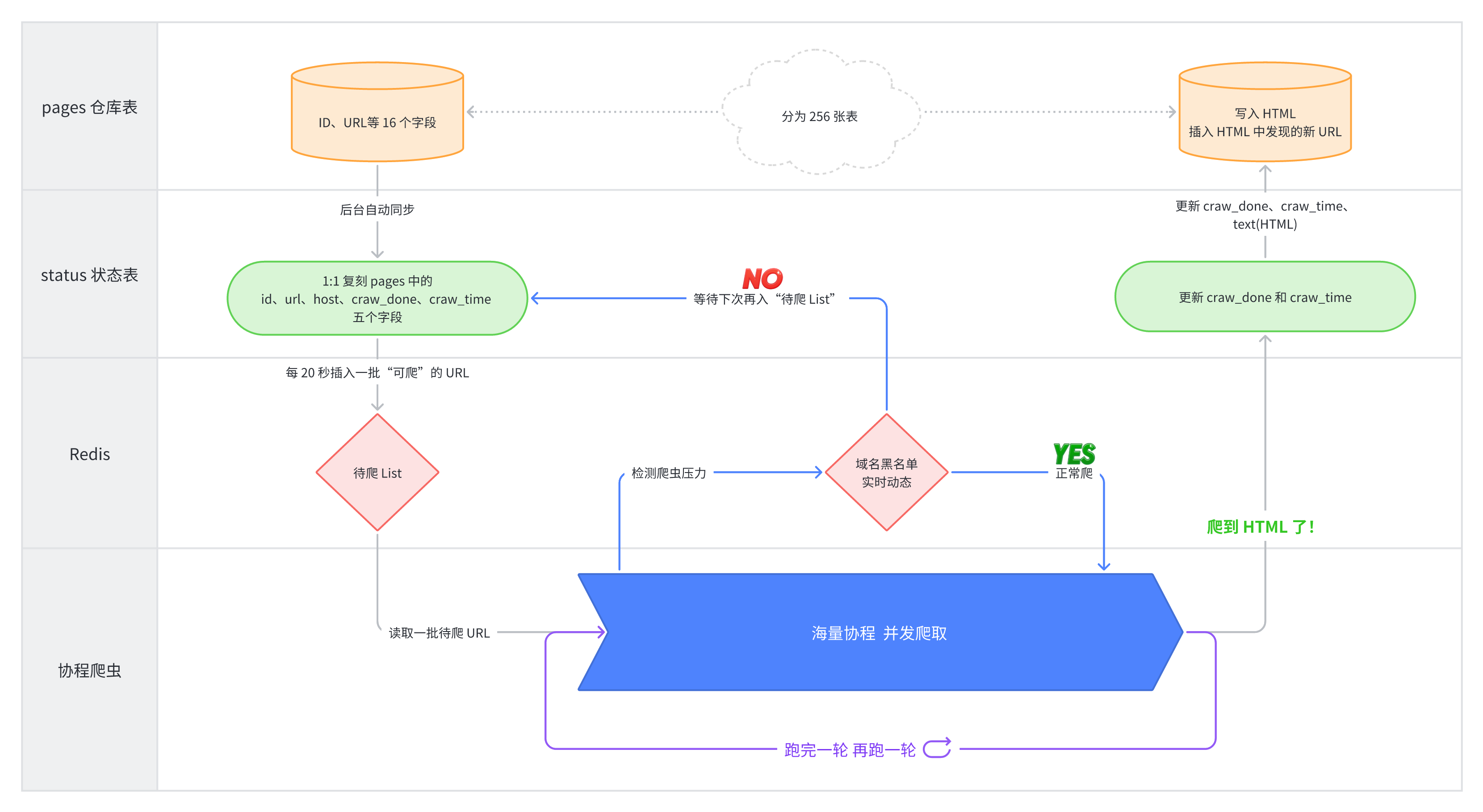
}真实的爬虫运行架构图
生产环境中的爬虫由于需要爬取数以亿计的网页,其运行架构是非常复杂的,笔者的开源项目 DIYSearchEngine 真实的爬虫架构如图 3-3 所示。